Serverless computing will spell the end for MVC architectures
Cloud architects must be good molecular chemists in the era of serverless computing. Wondering what chemistry has to do with cloud computing? Well, so did I, until I stumbled myself into an interesting discovery.
Let me make some assumptions. You are not a chemistry major. You are not interested in a detailed explanation of physical chemistry. These assumptions really help me because chemistry wasn’t my most favourite subject and I doubt whether I can tell you the difference between Alkanes and Alkenes.
On the other hand, the old adage that a little knowledge is dangerous in the wrong hands completely applies to me!
Here are a few nuggets to bring us closer:
- In the new and improved periodic table, elements are serverless functions
- Every element can be combined with other elements to create complex molecules
- Molecules provide minimum viable functionality based on their capabilities
- Applications have many different molecule clusters based on their performance, functionality and primary role
Serverless computing is making us completely rethink cloud application architectures. Deployments are simple because we don’t have to manage server infrastructure and the pay as you use model lowers operating costs since we pay only for execution time.
Even though AWS Lambda is well known, Google's AppEngine has been around for far longer and is the original serverless computing framework. In AppEngine, standard instances are actually serverless instances while flexible instances are container bound. Microsoft rounds off the list with Azure Cloud Functions.
But before we go further, let us model a simple real time document application. This application allows us to create documents, fill them with data, view them in any manner of our pleasing and serve them out in various other forms. It is a real time document, so we can view changes as they happen.
We shall accept that all data can be retrieved or inserted using the cloud provider’s storage service (file bucket or database) and hence we will not get distracted from our primary focus which is the application structure.
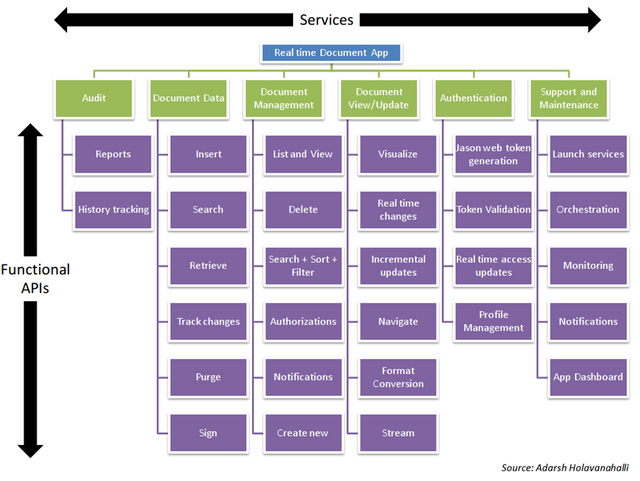
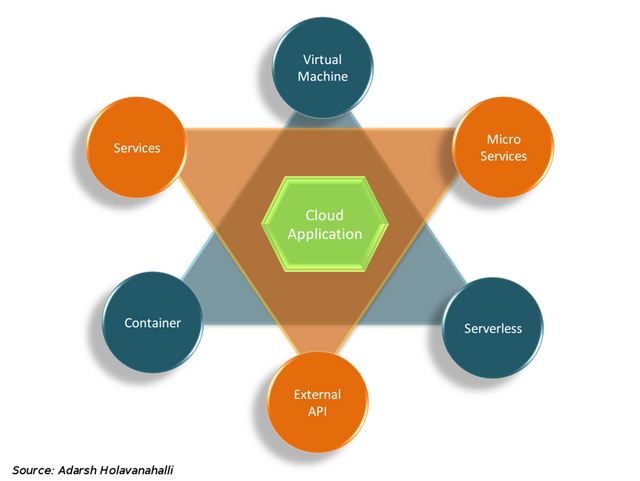
The application structure tells us that roles are called out into services and functionality is extruded as APIs. In reality, it could be a bunch of APIs for each functional box. Documents can be created, data inserted as well as retrieved and ultimately each document can be viewed based on a limited field of vision. We have glossed over some its intricacies but this simplistic explanation will do for now.
The corresponding minimal service deployment architecture would lead us to the figure below:
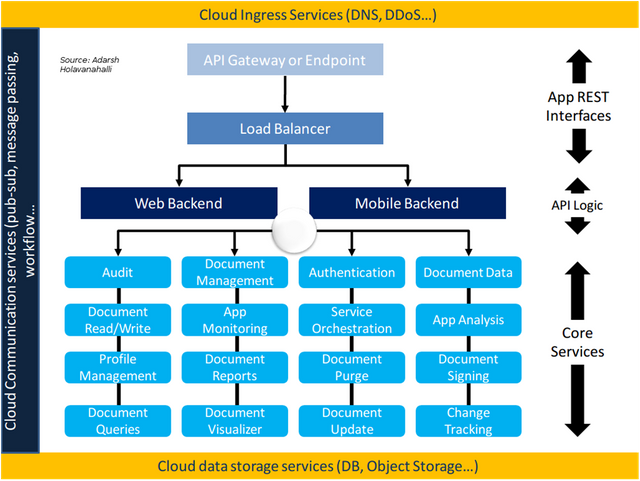
Serverless computing model
The golden rule of serverless computing is to be critically aware of the amount of time you need to execute computing elements in your application. A typical architect will divide the problem into compute heavy services and data heavy services. Data heavy services are part of a data pipeline and store/stream data on a regular basis.
So it makes sense to know some fundamental metrics of design as we map our services into functions:
- CPU speed: The number of Ghz/second you require for processing which will be billed in fixed increments
- Memory: Memory in GB/second or MB/second to accompany the selected CPU configuration. This will also be billed in fixed increments
- Instantiations: The number of times you may end up running the function. There may or may not be a instance launch cost
- Network Consumption: Network transfer in terms of GB/second. Most providers would bill this on actual and hence it is does not affect our decision making
It is also wise to remember that serverless functions are event driven, time bound, carry no state and run to completion.
Separate the event from event handling
The hardest part of moving to a serverless environment is to make it stateless. Services as well as many micro services are inherently stateful and can be a hard nut to crack. If you are running a Nodejs application then it is a simple matter because it is already an event driven model.
I have seen entire Nodejs applications packed into a single serverless computing element. In other words, you could run a micro service as a single function. However, this is not advisable because reusability is compromised and we lose the economic advantage.
But if not then you have to do the hard work and port it over. This means that we need to design independent functions that can be invoked one or more times and may not necessarily be idempotent. There should be no synchronization requirement across such functions and hence many instances could be executing in parallel. Any coordination must be done through storage or message passing layers. Since each function instance is executed only once per request, there can be no pipeline of commands for it work on.
The result of such an exercise is shown below:
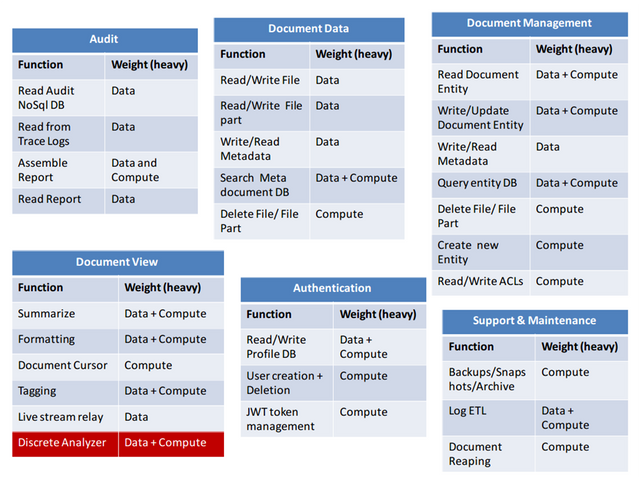
As the graphic shows, we divided up our application services into independently executable functions that can now be possible serverless candidates. We have weighted the functions based on their affinity and this will help us to decide whether we need more memory or more processing speed. Here is a quick example:
If our data read/write function will generally do transfers of 1000-2000 records at a time and if the combined in memory footprint is 1MB per record, then we are looking at 2.25 GB of memory. Its CPU speed can be as low as 2 GHz, since it behaves as a simple data pipeline
Refactor so that incompatible code is moved higher into the API layer
There are four reasons why our functions would need to be refactored.
One is that there is an indefinite amount of synchronous waiting in the function and it cannot be pushed back to the client app. Second, there is the chance that one function will call the other. Neither of these reasons are show stoppers but both will create architectural vulnerabilities and create complex pricing scenarios.
A third reason is if the function needs to maintain shared state between different invocations and the state cannot be maintained on persistent storage. A case in point is real time discrete analysis of the document (highlighted in the figure above) used by audit scans or cyber surveillance systems.
The fourth reason is that most serverless runtimes don’t allow dependencies on operating system provided libraries. E.g. a function that uses native extensions like external C libraries.
It is then safer to refactor the incompatible code and move it into VMs or containers.
Does this not remind us of programs and libraries?
gcc –c App.c –llibdoc –o Application
Serverless elements are exactly like libraries that we use in our everyday programming. They are active libraries that can be deployed at any location based on integration with cloud services. In fact if you think of them as libraries of functions then you will group them based on their usage, functionality, performance characteristics and operational dependencies.
Here is a deployment layout comparing the standard version with serverless computing:
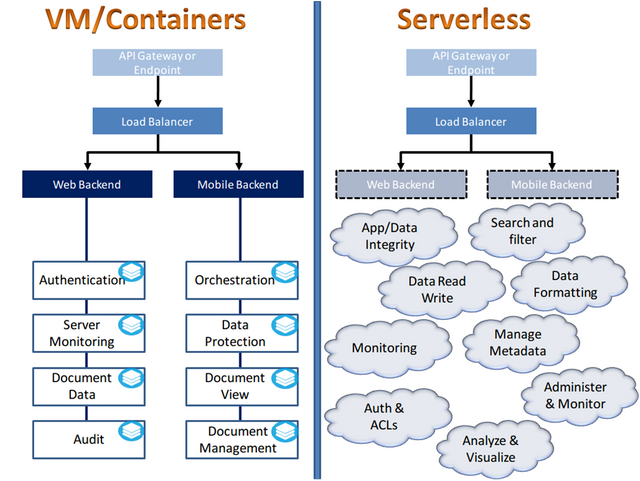
There are some very significant benefits:
- No servers: There are some installations which leave ingress to the API gateway and everything else to the serverless functions. Others preserve the web/mobile backend and disintegrate the rest. As a programmer, a serverless installation can be managed completely without significant devops skills
- No M in MVC: The model code may exist in the web/mobile backend servers but the work is not done in the model anymore. It may very well give rise to VC architectures in the future
- No VM sprawl: In a standard architecture, application servers are very dense with all the functionality packed into them. Hence many more permanent instances exist as the load scales up and down. In the serverless model, functions are instantiated on demand and managing their footprint is easy as long as there is focussed design.
Everything is not hunky dory in serverless land
Serverless computing comes with great responsibility and as an architect we must be extremely aware of fundamental issues that go hand in hand.
There is no way back once you go serverless. You are wedded to the providers infrastructure and you cannot get out.
Sandbox testing has to be done in the cloud and that is a bummer
Securing the application becomes harder because you have increased the number of attack vectors by slimming down the controller-model pair.
Deployments are tricky because you still have to program the serverless manifest. Cascading calls from one instance to the other have to be pre-programmed in the manifest, which is painful.
Configuration management in distributed applications at scale is always tricky and even more so because there could be a large number of serverless functions for deployment.
Summary
Architecting an application has become an exercise in chemistry. Now that we are able to disintegrate the application, we need to know how to mix them back together. Balance this equation right here!

Kneel Serverless Computing! Arise Molecular Computing!
Serverless computing will breed an entire generation of companies that don’t have the technical expertise to manage infrastructure. Is this a good thing? It is really good until you consider that the cloud provider has you completely locked in.
It will have far reaching impact on simplifying application frameworks. Is it for the better? It is fantastic for the programmer and terrible for the company that employs him/her. Application architecture expertise will shift from the company to the cloud provider. Solutions will become standardized and less innovative. It will force a rip and replace of existing architectures in many cases that always is expensive.
Cloud expenses and billing become far more transparent and decisive. Is this what we wanted? Today, application sizing is terribly inaccurate because of VM/container cost overruns. If the design is accurate the expense will become predictable as well. In other words, your cost will become a direct factor of your scaling requirements and not of your architecture
Serverless computing will displace containers and virtual machines. Is this good news? It is really bad news for enterprise infrastructure vendors but great for everyone else. Of course it is also unstoppable because of its overriding benefits.
Let me know what you think about how far serverless computing will go?