Tensorflow入门——Keras处理分类问题,Classification with Keras
Tensorflow 和 Keras 除了能处理前一篇文章提到的回归(Regression,拟合&预测)的问题之外,还可以处理分类(Classfication)的问题。
这篇文章我们就介绍一下如何用Keras快速搭建一个线性分类器或神经网络,通过分析病人的生理数据来判断这个人是否患有糖尿病。
同样的,为了方便与读者交流,所有的源代码都放在了这里:
https://github.com/zht007/tensorflow-practice
1. 数据的导入
数据的csv文件已经放在了项目目录中,也可以去Kaggle下载。
2.数据预处理
2.1 Normalization(标准化)数据
标准化数据可以用sklearn的工具,但我这里就直接计算了。要注意的是,这里没有标准化年龄。
cols_to_norm = ['Number_pregnant', 'Glucose_concentration', 'Blood_pressure', 'Triceps',
'Insulin', 'BMI', 'Pedigree']
diabetes[cols_to_norm] = diabetes[cols_to_norm].apply(lambda x: (x - x.min()) / (x.max() - x.min()))
2.2 年龄分段
对于向年龄这样的数据,通常需要按年龄段进行分类,我们先看看数据中的年龄构成。
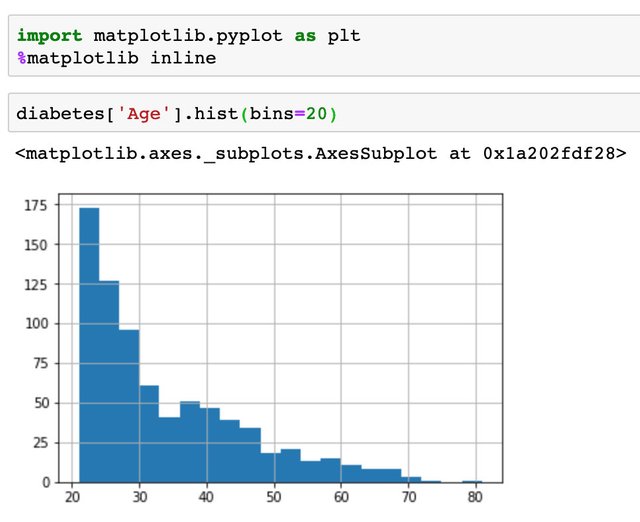
可以通过panda自带的cut函数对年龄进行分段,我们这里将年龄分成0-30,30-50,50-70,70-100四段,分别标记为0,1,2,3
bins = [0,30,50,70,100]
labels =[0,1,2,3]
diabetes["Age_buckets"] = pd.cut(diabetes["Age"],bins=bins, labels=labels, include_lowest=True)
3.4 训练和测试分组
这一步不用多说,还是用sklearn.model_selection 的 train_test_split工具进行处理。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x_data,labels,test_size=0.33, random_state=101)
3. 用Keras搭建线性分类器
与前一篇文章中介绍的线性回归模型一样,但线性分类器输出的Unit 为 2 需要加一个"sorftmax"的激活函数。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Activation
from tensorflow.keras.optimizers import SGD,Adam
from tensorflow.keras.utils import to_categorical
model = Sequential()
model.add(Dense(2,input_shape = (X_train.shape[1],),activation = 'softmax'))
需要注意的是标签y需要进行转换,实际上是将一元数据转换成二元数据(Binary)的"One Hot"数据。比如原始标签用"[1]"和"[0]"这样的一元标签来标记"是"“否”患病,转换之后是否患病用"[1 , 0]"和"[0 , 1]"这样的二元标签来标记。
y_binary_train= to_categorical(y_train)
y_binary_test = to_categorical(y_test)
同样可以选用SGD的优化器,但是要注意的是,在Compile的时候损失函数要选择"categorical_crossentropy"
sgd = SGD(0.005)
model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics=['accuracy'])
4. 分类器的训练
训练的时候可以直接将测试数据带入,以方便评估训练效果。
H = model.fit(X_train, y_binary_train, validation_data=(X_test, y_binary_test),epochs = 500)
5. 训练效果验证
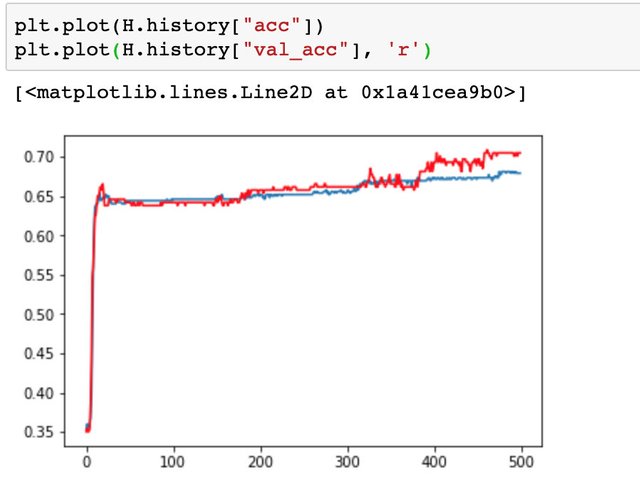
训练效果可以直接调用history查看损失函数和准确率的变化轨迹,线性分类器的效果还不错。
6. 改用神经网络试试
这里我在model中搭建一个20x10的两层全连接的神经网络,优化器选用adam
model = Sequential()
model.add(Dense(20,input_shape = (X_train.shape[1],), activation = 'relu'))
model.add(Dense(10,activation = 'relu'))
model.add(Dense(2, activation = 'softmax'))
adam = Adam(0.01)
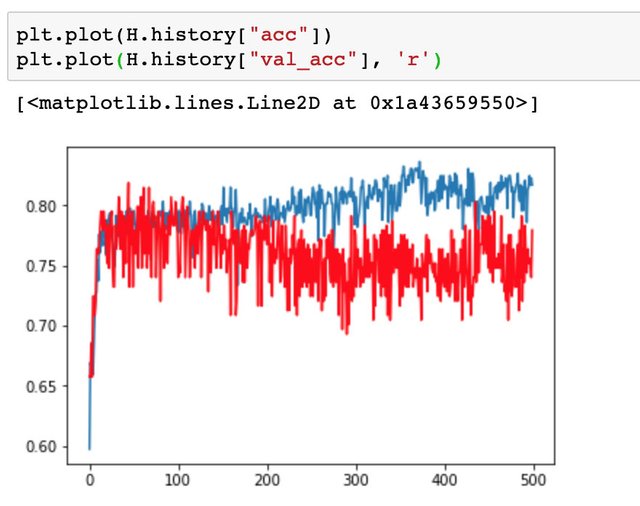
可以看到,虽然精确度比采用线性分类器稍高,但是在200个epoch之后,明显出现过拟合(Over fitting)的现象。
7. 用模型进行预测
同样的我们可以用训练得到的模型对验证数据进行预测,这里需要注意的是我们最后需要将二元数据用np.argmax转换成一元数据。
import numpy as np
y_pred_softmax = model.predict(X_test)
y_pred = np.argmax(y_pred_softmax, axis=1)
Congratulations @hongtao! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!