Des Variations de la vitesse de lecture sur les disques durs
Un petit disclaimer pour commencer : je parle ici de disques durs classiques avec des têtes de lectures au dessus de plateaux qui tournent. Ceci n’est pas applicable aux SSD qui n’ont, sur le plan physique, rien à voir.
De la théorie à la pratique
Théoriquement, la vitesse de lecture au début d’un disque est supérieure à celle à la fin de celui-ci (c’est pour cela que l’habitude a été prise de mettre le swap au début des disques). La cause en est que les premières pistes sont situées à l’extérieur et que lorsque la tête de lecture est à leur niveau, donc loin du centre du disque qui tourne à vitesse constante, elle passe au dessus d’une plus grande longueur de piste donc de plus de données pour une durée identique.
Avant de découvrir la possibilité tester la vitesse d’un disque dur à un endroit particulier dans celui-ci je n’imaginais pas que cette différence atteigne un facteur 2. À la découverte de cette possibilité l’idée d’explorer systématiquement un disque m’est venu. Cependant il ne fallait pas que les résultats soient faussés par d’autre utilisation du disque. En conséquence il fallait un disque inutilisé se qui raréfie les occasions de faire de tels tests ! Mais, suite à l’achat et au test d’un nouveau disque, c’est fait !
Le constat
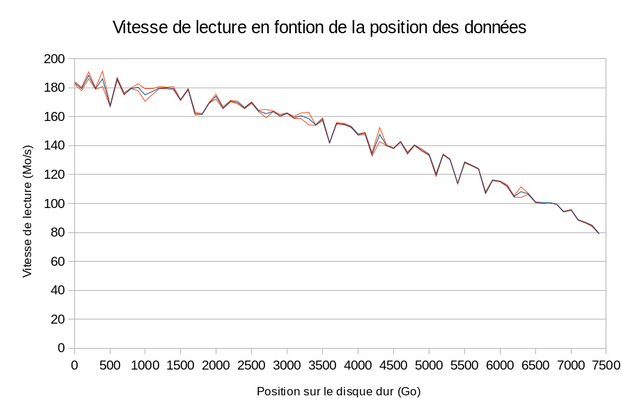
La vitesse de lecture supérieure à 180 mégaoctets par seconde en début de disque chute à 80 à la fin de celui-ci. Cette chute est de plus en plus rapide à mesure que nous nous approchons du centre physique (donc de la fin logique) du disque. Ceci est du au fait qu’en mesurant la position sur le disque en gigaoctets on a une vision déformée du disque physique. En effet les pistes étant plus longue à l’extérieur (début physique) elle contiennent plus de secteur et donc de données, se déplacer de 100 gigaoctets y correspond à un déplacement moindre en rayon que lorsqu’on est proche du centre.
Une curiosité apparaît : les pointes vers le bas à 500 Go, 1700 et 1800 Go, 3600 Go... Le calcul des écarts-types (en rouge sur le graphique : ∓ 2 écarts-types) permet d’estimer la dispersion des mesures et tend à montrer qu’il ne s’agit pas d’artefacts statistiques. Je ne sais pas à quoi elles correspondent. Peut-être à des secteurs gardés en réserves pour d’éventuelles ré-allocations, ou à des changements de piste ?
Les conséquences
En n’utilisant pas la fin du disque, il est possible de gagner en vitesse de lecture mais aussi en vitesse d’accès car il faut beaucoup de temps à la tête de lecture pour parcourir les pistes centrales par rapport au peu de données qu’elles contiennent. Que faire de cet espace ? Une partition qui vous servira à stocker des fichiers volumineux que vous utilisez rarement : des vidéos, images de distributions ou sauvegardes croisées avec d’autres machines par exemple.
Le script
Le script doit être lancé avec 2 arguments : le disque à analyser et la taille de celui-ci en centaines de gigaoctets... Mais attention : les constructeurs de disques mesurent la taille de ceux-ci en considérant qu’un téraoctet fait 1000 gigaoctets, que les gigaoctets font 1000 mégaoctets chacun qui font 1000 kilooctets pièce, etc. alors que les développeurs de logiciels considèrent des facteurs 1024 entre chaque unité. Il convient donc de calculer la taille « au sens du système d’exploitation » de votre disque. Pour un 8 To comme le mien, cela donne 74 (remarquez qu’on fini avec une troncature et non un arrondi) :
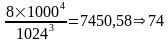
#!/bin/bash
echo "pos.(GB) vitesse(MB/sec) ecart-type(MB/sec)"
for i in `seq 0 $2`
do
sum=0
ssum=0
for j in `seq 1 10`
do
data=`hdparm -t --offset ${i}00 $1 | grep Timing`
n=0
for elem in $data
do
n=`expr $n + 1`
if [ $n = 14 ]
then
sum=$(echo "$sum + $elem" | bc -l)
ssum=$(echo "$ssum + ( $elem * $elem )" | bc -l)
fi
done
done
moy=$(echo "$sum / $j" | bc -l)
stdev=$(echo "sqrt ( ( $ssum - ( $sum * $moy ) ) / ( $j - 1 ) )" | bc -l)
echo "${i}00 $moy $stdev"
done
Intéressant ;-) ! Merci pour l' article :D !
Très bon article explicatif sur ce phénomène qui concerne le matériel de stockage informatique ! Upvoté à 100% !
Congratulations @ldespeyroux! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board of Honor
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Félicitations @ldespeyroux pour votre beau travail!
Ce post a attiré l'attention de @ajanphoto et a été upvoté à 100% par @steemalsace et son trail de curation comportant actuellement 28 upvotes .
De plus votre post apparaîtra peut-être cette semaine dans notre article de sélection hebdomadaire des meilleurs post francophones.
Vous pouvez suivre @steemalsace pour en savoir plus sur le projet de soutien à la communauté fr et voir d'autres articles qualitatifs francophones ! Nous visons la clarté et la transparence.
Rejoignez le Discord SteemAlsace
Pour nous soutenir par vos votes : rejoignez notre Fanbase et notre Curation Trail sur Steemauto.com. C'est important pour soutenir nos membres, les steemians et Witness francophones ICI!
@ajanphoto