핸즈온 머신러닝 책을 공부하면서 정리하고 있습니다. 10장 인공 신경망 소개 #7
머신러닝에 대한 책을 5권에서 6권정도 읽고 있는데 잘 이해가 안되는 부분이 참 많습니다. 그래서 내용을 필사하면서 직접 코드를 입력하면서 반복해서 보고 있습니다. 작년에 보았던 내용들보다 더 많이 이해가 되고 점점 쉽게 느껴지는 부분도 생기네요. ^^ 놀라운 변화 입니다.
아래와 같은 순서로 책을 보시면됩니다. 파이썬 언어를 공부해야 합니다. => 판다스를 사용할 수 있어야 합니다. => 머신러닝, 딥러닝을 공부할 수 있습니다. 제가 정리한 글에 있습니다. 이런 순서로 공부하고 선형대수나 미분에 대한 내용을 개발자를 위한 수학책으로 따로 정리하면 될 것 같습니다. 좌절과 희열을 반복하면서 보고 있는데 점점 좌절보다는 희망을 보고 있습니다. 기계학습과 강화 학습을 공부하시는 모든 분들 화이팅입니다. ~~~~
https://steemit.com/kr/@papasmf1/73cj22
핸즈온 머신러닝 책의 소스는 아래의 깃허브에 있습니다. 참고하실 수 있습니다.
https://github.com/rickiepark/handson-ml
제가 테스트하고 실습하는 환경은 맥에 아나콘다 최근 패키지를 설치해서 주피터랩으로 실행하고 있습니다. 아나콘다 패키지를 사용하는 경우에 텐서플로는 쉽게 설치할 수 있습니다. ^^
10장 인공신경망 소개를 정리해 보았습니다. ^^
지능적인 기계에 대한 영감을 얻기 위해서는 뇌의 구조를 살펴보는 것이 합리적입니다. 이것이 인공 신경망 artificial neural networks(ANN)을 만들어낸 핵심 아이디어 입니다.
인공 신경망은 딥러닝의 핵심입니다 인공 신경망은 다재다능하고 강력하고 확장성이 좋ㄷ아서 수백만 개의 이미지를 분류하거나 음성 인식 서비스의 성능을 높이거나 매울 수억 명의 사용자에게 가장 좋은 비디오를 추천해주거나, 세계 바독 참피언을 이기기 위해 수백만 개의 기보를 익히고 자기 자신과 게임하면서 학습하는(딥마인드의 알파고) 경우 등 아주 복잡한 대규모 머신러닝 문제를 다루는데 적합합니다.
10.1 생물학적 뉴런에서 인공 뉴런까지
1943년 신경생리학자 워런 맥컬록과 수학자 월터 피츠가 이를 처음 소개했습니다.
1960년대까지 인공 신경망의 초기 성공은 곧 지능을 가진 기계와 대화를 나눌 수 있을 것이란 믿음을 널리 퍼뜨렸습니다. 이 역속이 지켜질 수 없다는 것이 명백해지면서 다른 분야로 투자가 옮겨갔고 인공 신경망은 긴 침체기에 들어서게 됩니다.
1990년대까지는 대부분의 연구자가 서포트 벡터 머신 같은 다른 강력한 머신러닝 기법을 선호했습니다
10.1.1 생물학적 뉴런
생물학적 뉴런을 간단히 살펴보도록 합니다. 이 이상하게 생긴 세포는 대부분 동물의 대뇌 피질에서 발견되며 핵을 포함한 세포체 cell body와 세포의 복잡한 구성 요소로 이루어져 있습니다. 그리고 수상돌기 dendrite라는 나뭇가지 모양의 돌기와 축삭돌기 axon라는 아주 긴 돌기 하나를 가지고 있습니다. 축살돌기의 길이는 세포체의 몇 배 정도에서 4만 배까지 되기도 합니다. 축살돌기의 끝은 축삭끝가지 telodendria라 불리는 여러 개의 가지로 나뉘고, 이 가지의 끝은 시냅스 말단 synaptic terminals(또는 간단히 시냅스 synapse)라고 불리는 미세한 구조이고 다른 뉴런의 수상돌기와 (또는 세포체에 직접) 연결되어 있습니다. 생물한적 뉴런은 이런 시냅스를 통해 다른 뉴런으로부터 짧은 전기 자극 신호 signal을 받습니다.
10.1.2 뉴런을 사용한 논리 연산
워런 맥컬록과 월터 피츠는 매우 단순한 생물학적 뉴런 모델을 제안했는데 나중에 이것이 인공뉴런이 되었습니다. 이 모델은 하나 이상의 이진 입력과 하나의 이진 출력을 가집니다. 인공 뉴런은 단순히 일정 개수의 입력이 활성화되었을 때 출력을 내보냅니다.
10.1.3 퍼셉트론
퍼셉트론 Perceptron은 가장 간단한 인공 신경망 구조 중 하나로 1957년에 프랑크 로젠블라트가 제안했습니다. 퍼셉트론은 TLU threshold logic unit라는 조금 다른 형태의 인공 뉴런을 기반으로 합니다.
퍼셉트론은 층이 하나뿐인 TLU로 구성되니다. 각 뉴런은 모든 입력에 연결되어 있습니다. 이 뉴런은 무엇이 주입되든 입력을 그냥 출력으로 통과시킵니다. 보통 거기에 편향 특성이 더해집니다. 전형적으로 이 편향 특성은 항상 1을 출력하는 특별한 종류의 뉴런인 편향 뉴런 bias neuron으로 표현됩니다.
1969년 퍼셉트론이란 제목의 논문에서 마빈 민스키와 시모어 페퍼트는 퍼셉트론의 여러 가지 심각한 약점을 언급했습니다. 특히 실제로 일부 간단한 문제를 풀 수 없습니다. 하지만 연구자들은 퍼셉트론에서 더 많은 것을 기대했기 때문에 실망이 컸습니다. 결국 많은 연구자가 논리학, 문제 해결, 검색 같은 고수준의 문제를 연구하기 위해 이 분야(즉 신경망 연구)를 떠났습니다.
그러나 여러 퍼셉트론을 쌓아올려 일부 제약을 줄일 수 있다는 사실이 밝혀졌습니다. 이런 인공 신경망을 다층 퍼셉트론 Multi-Layer Perceptron(MLP)라고 합니다. 다층 퍼셉트론은 XOR문제를 풀 수 있습니다.
10.1.4 다층 퍼셉트론과 역전파
다층 퍼셉트론은 (통과) 입력층 하나와 은닉층 hidden layer라고 불리는 하나 이상의 TLU 층과 마지막 층인 출력층 output layer으로 구성됩니다. 출력층을 제외하고 모든 층은 편향 뉴런을 포함하며 다음 층과 완전히 연결되어 있습니다. 인공 신경망의 은닉층이 2개 이상일 때 이를 심층 신경망 deep neural network(DNN)이라고 합니다.
1986년 역전파 backpropagation 훈련 알고리즘을 소개하는 획기적인 논문이 공개되었습니다. 요즘에는 이를 후진 모드 자동 미분을 사용하는 경사 하강법으로 기술합니다.
알고리즘이 각 훈련 샘플을 네트워크에 주입하고 연속되는 각 층의 뉴런마다 출력을 계산합니다. 이는 예측을 만들 때와 간은 정방향 계산입니다. 그런 다음 네트워크의 출력 오차(기댓값과 네트워크 실제 출력과의 차이)를 계산합니다. 그리고 각 출력 뉴런의 오차에 마지막 은닉층의 뉴런이 얼마나 기여했는지 측정합니다. 그런 다음 이전 은닉층의 뉴런이 여기에 또 얼마나 기여했는지 측정합니다. 이런 식으로 입력층에 도달할 때까지 계속 측정합니다. 이 역방향 과정은 오차 그래디언트를 후방으로 전파함으로써 네트워크의 모든 연결 가중치에 대한 오차 그래디언트를 효율적으로 계산합니다. 그래서 이름이 역전파입니다.
더 간단히 말하면 각 훈련 샘플에 대해 역전파 알고리즘이 먼저 예측을 만들고(정방향 계산), 오차를 측정하고, 그런 다음 역방향으로 각 층을 거치면서 각 연결이 오차에 기여한 정도를 측정합니다(역방향 계산). 마지막으로 이 오차가 감소하도록 가중치를 조금씩 조정합니다(경사 하강법 스텝).
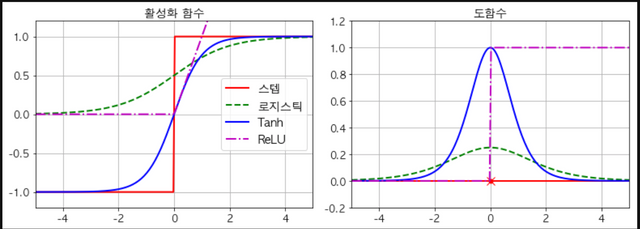
널리 쓰이는 활성화 함수는 2개
히이퍼볼릭 탄젠트 함수(쌍곡 탄젠트 함수)
ReLU 함수
신호가 (입력에서 출력으로) 한 방향으로만 흐르기 때문에 이런 구조를 피드 포워드 신경망 feed forward neural networkI(FNN)이라고 합니다.
10.2 텐서플로의 고수준 API로 다층 퍼셉트론 훈련하기
텐서플로로 다층 퍼셉트론(MLP)를 훈련시키는 가장 간단한 방법은 사이킷런과 호환되는 고수준 API인 TF.Learn을 사용하는 것입니다. DNNClassifier파이썬 클래스는 여러 개의 은닉층과 클래스의 확률 추정을 위한 소프트맥스 출력층으로 구성된 심층 신경망을 매우 쉽게 훈련시켜줍니다.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # 꽃잎 길이, 꽃잎 너비
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(max_iter=100, random_state=42)
per_clf.fit(X, y)
y_pred = per_clf.predict([[2, 0.5]])
y_pred
array([1])
a = -per_clf.coef_[0][0] / per_clf.coef_[0][1]
b = -per_clf.intercept_ / per_clf.coef_[0][1]
axes = [0, 5, 0, 2]
x0, x1 = np.meshgrid(
np.linspace(axes[0], axes[1], 500).reshape(-1, 1),
np.linspace(axes[2], axes[3], 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = per_clf.predict(X_new)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
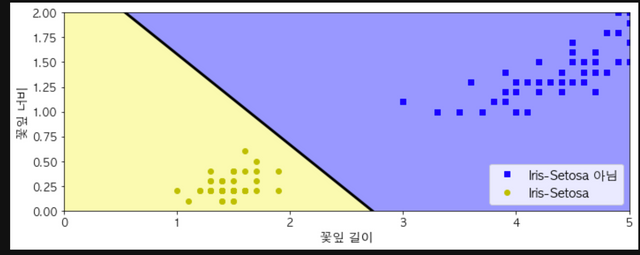
plt.plot(X[y==0, 0], X[y==0, 1], "bs", label="Iris-Setosa 아님")
plt.plot(X[y==1, 0], X[y==1, 1], "yo", label="Iris-Setosa")
plt.plot([axes[0], axes[1]], [a * axes[0] + b, a * axes[1] + b], "k-", linewidth=3)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#9898ff', '#fafab0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
plt.xlabel("꽃잎 길이", fontsize=14)
plt.ylabel("꽃잎 너비", fontsize=14)
plt.legend(loc="lower right", fontsize=14)
plt.axis(axes)
save_fig("perceptron_iris_plot")
plt.show()
#활성화 함수
def logit(z):
return 1 / (1 + np.exp(-z))
def relu(z):
return np.maximum(0, z)
def derivative(f, z, eps=0.000001):
return (f(z + eps) - f(z - eps))/(2 * eps)
z = np.linspace(-5, 5, 200)
plt.figure(figsize=(11,4))
plt.subplot(121)
plt.plot(z, np.sign(z), "r-", linewidth=2, label="스텝")
plt.plot(z, logit(z), "g--", linewidth=2, label="로지스틱")
plt.plot(z, np.tanh(z), "b-", linewidth=2, label="Tanh")
plt.plot(z, relu(z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
plt.legend(loc="center right", fontsize=14)
plt.title("활성화 함수", fontsize=14)
plt.axis([-5, 5, -1.2, 1.2])
plt.subplot(122)
plt.plot(z, derivative(np.sign, z), "r-", linewidth=2, label="Step")
plt.plot(0, 0, "ro", markersize=5)
plt.plot(0, 0, "rx", markersize=10)
plt.plot(z, derivative(logit, z), "g--", linewidth=2, label="Logit")
plt.plot(z, derivative(np.tanh, z), "b-", linewidth=2, label="Tanh")
plt.plot(z, derivative(relu, z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
plt.title("도함수", fontsize=14)
plt.axis([-5, 5, -0.2, 1.2])
save_fig("activation_functions_plot")
plt.show()
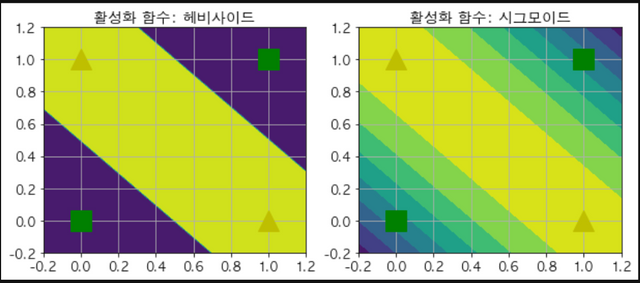
def heaviside(z):
return (z >= 0).astype(z.dtype)
def sigmoid(z):
return 1/(1+np.exp(-z))
def mlp_xor(x1, x2, activation=heaviside):
return activation(-activation(x1 + x2 - 1.5) + activation(x1 + x2 - 0.5) - 0.5)
x1s = np.linspace(-0.2, 1.2, 100)
x2s = np.linspace(-0.2, 1.2, 100)
x1, x2 = np.meshgrid(x1s, x2s)
z1 = mlp_xor(x1, x2, activation=heaviside)
z2 = mlp_xor(x1, x2, activation=sigmoid)
plt.figure(figsize=(10,4))
plt.subplot(121)
plt.contourf(x1, x2, z1)
plt.plot([0, 1], [0, 1], "gs", markersize=20)
plt.plot([0, 1], [1, 0], "y^", markersize=20)
plt.title("활성화 함수: 헤비사이드", fontsize=14)
plt.grid(True)
plt.subplot(122)
plt.contourf(x1, x2, z2)
plt.plot([0, 1], [0, 1], "gs", markersize=20)
plt.plot([0, 1], [1, 0], "y^", markersize=20)
plt.title("활성화 함수: 시그모이드", fontsize=14)
plt.grid(True)
10.3 텐서플로의 저수준 API로 심층 신경망 훈련하기
네트워크의 구조를 더 상세히 제어하고 싶다면 텐서플로의 저수준 파이썬 API가 나을지도 모릅니다. 이 절에서는 저수준 API로 이전과 같은 모델을 만들고 MNIST데이터셋에서 훈현하기 위해 미니배치 경사 하강법을 구현해 보겠습니다. 첫번째 스텝은 텐서플로 계산 그래프를 만드는 구성 단계이고, 두 번째 스텝은 실제로 이 그래프를 실행해 모델을 훈련시키는 실행 단계입니다.
10.3.1 구성 단계
입력과 출력 크기를 지정하고 은릭층의 뉴런 수를 설정합니다.
import tensorflow as tf
n_inputs = 28 * 28. #MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X의 크기는 일부분만 정의됩니다. 우리가 아는 것은 ‘첫 번째 차원을 따라 샘플이 있고 두 번째 차원을 따라 특성이 있는’ 2D 텐서(즉, 행렬)라는 점입니다. 특성의 수는 28 * 28(픽셀당 하나의 특성)입니다. 하지만 아직 훈련 배치에 몇 개의 샘플이 포함될지 모릅니다. 그래서 X의 크기는 (None, n_inputs)입니다. 비슷하게 y는 값이 샘플당 하나인 1차원 텐서라는 것은 알지만, 역시 지금 시점엔 훈련 배치의 크기를 알 수 없어 이 크기는 (None)입니다.
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
플레이스홀더 X는 입력층의 역할을 합니다. 실행 단계 동안 한 번에 하나씩 훈련 배치로 바뀌게 됩니다. 이제 두 개의 은닉층과 하나의 출력층을 만들어야 합니다. 두 은닉층은 거의 같고 연결된 입력과 뉴런 수만 다릅니다.
10.4 신경망 하이퍼라라미터 튜닝하기
신경망의 유연성은 중요한 단점이 되기도 합니다. 즉, 조절해야 할 하이퍼파라미터가 많아집니다. 상상할 수 있는 어떤 네트워크 토폴로지 network topology(뉴런이 연결된 방식)도 사용할 수 있을 뿐만 아니라 간단한 다층 퍼셉트론조차도 층 수나 층마다의 뉴런 수, 각 층에서 사용하는 활성화 함수, 가중치 초기화 방식 등을 바꿀 수 있습니다. 어떤 하이퍼파라미터의 조합이 최적인지 어떻게 알 수 있을까요?
물론 이전 장에서 한 것처럼 적절한 하이퍼파라미터를 찾기 위해 교차 검증을 활용한 그리드 탐색을 할 수 있습니다. 하지만 조정할 하이퍼파라미터가 많고 대규모 데이터셋에 신경망을 훈련할 때 오랜 시간이 걸리기 때문에 주어진 시간 안에 전체 하이퍼파라미터 공간 중 작은 부분만 탐색할 수 있습니다. 이런 경우엔 2장에서 이야기한 랜덤 탐색을 사용하는 것이 낫습니다.
10.4.1 은닉층의 수
많은 문제가 은닉층 하나로 시작해도 쓸 만한 결과를 얻을 수 있습니다. 사실 은닉층이 하나인 다층 퍼셉트론이더라도 뉴런 수가 충분하면 아주 복잡한 함수도 모델링할 수 있다는 것이 밝혀졌습니다. 이런 사실 때문에 오랬동안 연구자들은 더 깊은 신경망을 연구할 필요를 느끼지 못했습니다. 하지만 심층 신경망이 얕은 신경망보다 파라미터 효율성이 훨씬 좋다는 것을 간과했습니다. 심층 신경망은 복잡한 삼수를 모델링하는 데 얕은 신경망보다 훨씬 적은 수의 뉴런을 사용하기 때문에 더 빠르게 훈련됩니다.
왜 그런지 이해하기 위해 복사하여 붙여넣기 기능이 없는 드로잉 소프트웨어를 사용해 숲을 느려야 한다고 생각해봅시다. 이 경우 나무, 가지, 잎을 하나하나 모두 개별적으로 그려야 할 것입니다. 만일 잎 하나를 그리고 이를 나뭇가지에 복사하여 붙여넣고, 이 가지를 복사하여 붙여넣기로 나무를 만들고, 이 나무를 복사하여 붙여넣기로 숲을 만들 수 있다면 금세 일을 마칠 수 있을 것입니다. 실제로 데이터는 이런 계층적 구조를 가진 경우가 많아서 심층 신경망은 자동적으로 이런 점에서 유리합니다. 아래쪽 은닉층은 저수준의 구조를 모델링하고(예를 들면 여러 가지 방향이나 형태의 선분), 중간 은닉층은 저수준의 구조를 연결하여 중간 수준의 구조를 모델링합니다(예를 들면 사각형 원). 그리고 가장 위쪽 은닉층과 출력층은 이런 중간 수준의 구조를 연결하여 고수준의 구조를 모델링합니다(예를 들면 얼굴).
10.4.2 은닉층의 뉴런 수
입력층과 출력층의 뉴런 수는 해당 작업에 필요한 입력과 출력의 형태에 따라 결정됩니다. 예를 들어 MNIST는 28 * 28 = 784개의 입력 뉴런과 10개의 출력 뉴런이 필요합니다. 인닉층의 구성 방식은 일반적으로 각 층의 뉴런을 점점 줄여서 깔때기처럼 구성합니다. 저수준의 많은 특성이 고수준의 적은 특성으로 합쳐질 수 있기 때문입니다.
단순 접근 방식은 실제 필요한 것보다 더 많은 층과 뉴런을 가진 모델을 선택하고, 그런 다음 과대적합되지 않도록 조기 종료 기법을 사용하는 것입니다. 이를 ‘스트레치 팬츠 stretch pants’방식이라고 부릅니다. 즉, 나에게 맞는 사이즈의 바지를 찾느라 시간을 낭비하는 대신에 그냥 큰 스트레치 팬츠를 사고 나중에 알맞게 줄이는 것입니다.
짱짱맨 호출에 응답하였습니다.