Some people say that the journey of artificial intelligence is the sea of stars, but can it really subvert the development of new drugs?
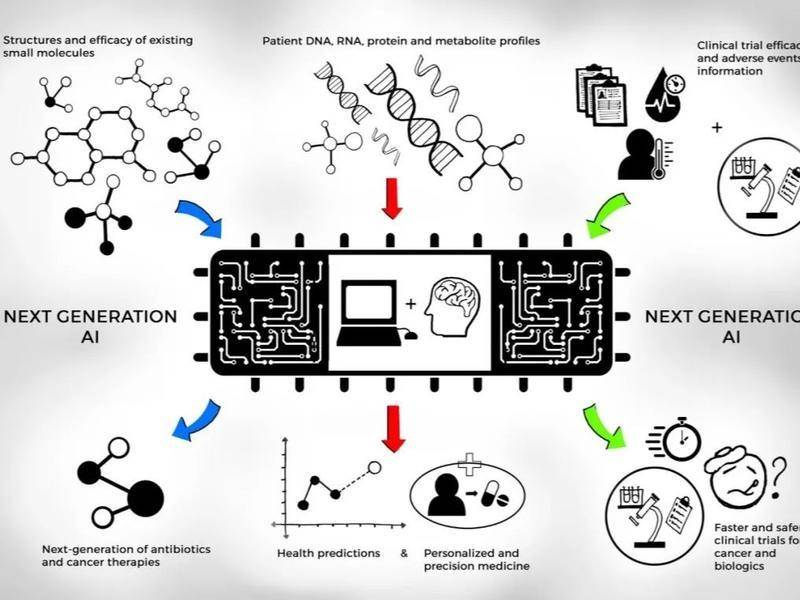
Artificial intelligence (AI) is highly dependent on high-quality and marked big data. In a new drug innovation field driven by biology hypotheses, inefficiency, and trial and error, there is no doubt that this will significantly enhance certain stages in the drug development process. s efficiency. However, regardless of whether the heroes of the youth have emerged from the thriving IT entrepreneurship elites or who have decades of research and development experience in the veterans of the medical industry, they all lack a rational understanding of artificial intelligence + new drug development.
In view of this, if you hang one million, I would like to share our views and attitudes on the development of artificial intelligence + new drugs, and understand the disease-imaging diagnosis and the discovery of new biological mechanisms/new targets and design drug-activity from two aspects. Predicting and producing and synthesizing compound libraries, and exploring the actual and deficiency of artificial intelligence in the development of new drugs.
First, the rise of artificial intelligence
Heaven and earth, yellow, human beings as a creature possessing NI (Natural Intelligence), was born in the wild in the universe. From upright walking, slash-and-burn farming, steam motors, moon landing, to the ubiquitous Internet, humans have realized self-knowledge in the exploration of the universe. From Aristotle’s metaphysics, to Newton's three laws of motion, to Einstein's theory of relativity, all this shines in the Milky Way.

Humans who are the lingua franca of all things are no longer satisfied with eating apples for wisdom, but they hope to create new intelligent life in the lonely universe - Artificial Intelligence. Time flies, just after the Deep Blue defeated Chess Master Kasparov in 1997, artificial intelligence swept the most complex human board game, Go. In less than a year, the name of artificial intelligence has changed from an unnamed AlphaGo dog to a Master who has never known one, and it has evolved to the point where people do not like to care about humanity and fight each other and learn from one another. AlphaGo Zero.
Artificial intelligence quickly became popular. Asimov’s "Three Laws" of robots seemed to be close at hand. Not only was the circle of friends full of exaggerated reports and speculations about artificial intelligence, such as the rumors of the looming of human jobs, even if it was rigorous and realistic. Academic circles and industrial circles are also full of enthusiasm. People often say “my friend Hu Shih’s artificial intelligence”. Public opinion will always focus on the pursuit of tomorrow’s investment community. It’s a big deal and it’s only a matter of time. Thunder first" weather.
In fact, strictly speaking, artificial intelligence is not considered a "new mine". It began at the 1956 Dartmouth Conference and has a history of more than 60 years. It covers a wide range of disciplines and technologies, including robotics, speech recognition, and natural language recognition. Processing, image recognition and processing, machine learning, and more. Although there have been ups and downs before, there have been no storms. In recent years, thanks to the rapid growth of computing power, the introduction of deep learning methods, and the rise of big data, this “three-axes” has contributed to the emergence of artificial intelligence in many industries. The biomedical industry in which the author is based is artificially fluent. One of the most important towns.
In the face of this current group of artificial intelligence companies, we always ask the ultimate question that all emerging technologies need to face: At what stage is the artificial intelligence currently in the Hype Cycle? Is artificial intelligence positive for other technologies currently available to PK? In the foreseeable future, what exactly can artificial intelligence do?
The journey of artificial intelligence can be stars and the sea, but the supply of advancement can not be a picture. The vision is not what we are interested in. After all, can DeepMind really "Solve intelligence. Use it to make the world a better place" than the Deep Thought told us that the ultimate answer to the universe is 42 - Sci-Fi Bible "The Galaxy Roaming Guide 》- To be much more practical.
Second, artificial intelligence for disease diagnosis, competition or cooperation?
In the entire medical field, disease diagnosis, especially medical imaging (X-ray, ultrasound, MRI, CT, PET, etc.) is the direction in which artificial intelligence is recognized.
In 2017, Arterys' imaging platform, Cardio AI, became the first FDA-approved first aided diagnostic tool to help physicians analyze cardiac MRI images, automatically depict ventricular contours in images, and calculate ventricular function-related parameters; Its Lung AI and Liver AI also received FDA approval to assist physicians in analyzing lung nodules and liver damage. In February of this year, Viz.AI’s ContaCT was also approved by the FDA for the analysis of CT scans of the brain to detect stroke-related signals (such as suspicious large blood vessel blockages) and promptly inform the doctor.
It is heartening that, recently, the FDA approved IDx's IDx-DR to be used independently for the initial screening of diabetic retinopathy and to determine if further evaluation and diagnosis by the doctor are required.
In addition to advances in the industry, work in the high-level journals of the academic community on artificial intelligence imaging is also common. In 2016, JAMA and Cell in 2018 had artificial intelligence in the diagnosis of eye diseases such as age-related macular degeneration and diabetic macular edema. Reported. In short, artificial intelligence has a high sensitivity and specificity in the identification of diseased images. The speed and reproducibility are also the advantages of artificial intelligence. Physicians are beginning to worry about whether they will be robbed of work by artificial intelligence.
The excellent performance of artificial intelligence in medical imaging diagnostics is not surprising at all. The catalyst for this round of artificial intelligence waves was ImageNet, a professor at Stanford University and chief scientist of Google Cloud, Li Feifei. Image diagnosis resulting from certain diseases has clearer logos and sufficient training sets. Artificial intelligence can achieve the same accuracy as doctors in image data sets.
However, the actual environment will be more complex than the conditions strictly controlled in the literature or in many human-computer PK contests. Although artificial intelligence reduces overfitting by introducing Dropout and DropConnect algorithms, the lack of data diversity still leads to the bias of artificial intelligence. The lack of generalization ability is even more helpless to rare diseases.
Second, the current artificial intelligence can only engage in specific types of smart behavior. There are many applicable conditions and scopes. For example, IDx-DR still requires professional operators to operate the fundus camera to obtain high-quality images, and it is necessary to exclude multiple types of images before use. Not applicable conditions such as persistent vision loss, blurred vision, proliferative retinopathy and retinal vein occlusion.
Once again, encountering certain equivocal images of the disease often requires the doctor to examine the patient during the film reading and combine the patient's previous medical history report to make a comprehensive judgment. This type of task that requires logical reasoning based on medical common sense seems to appear to artificial intelligence. Not easy. In the Winograd Model Challenge (a natural language problem of pronoun disambiguation, used to distinguish whether artificial intelligence is based on common sense to understand conversations or guesswork based on statistical data), artificial intelligence is defeated.
Finally, all AI work is only likely to be recognized by the medical community if it follows clinical guidelines. For example, IDx-DR, which is most like a doctor, is good at image interpretation of retinal imaging, and the US Diabetes Association’s position statement on screening for diabetic retinopathy in 2017 In the case of retinal imaging, there is E-class evidence of the classification system of evidence, and the FDA also clearly stated that the patient still needs a full set of eye examinations at 40 and 60 years of age and any visual problems, not to mention the artificial intelligence through the black box of the multilayer neural network. The results are not reassuring.
At the same time, medicine continues to advance and clinical guidelines will be revised, which may lead to the need to revisit the logo of the previous training set. Data identification work can be described as a labor-intensive type of work. Many people like Foxconn hire a large number of people, but these data identification factories do not appear in glossy news. Because of their professionalism, medical data logos require higher levels of identification personnel.
Artificial intelligence medical imaging is definitely the direction of the future, and it is expected that it will be widely used as a doctor's assistant in major hospitals to provide truly useful reference opinions on the diagnosis of various diseases. Only the current artificial intelligence has a long way to go from the media to promote "alternative doctors."
In fact, if you focus on the areas beyond human eyes, it may be another feasible path, such as simplifying the diagnosis of diseases to the molecular level. If AI chooses to make up for the lack of human capabilities rather than compete with humans, the probability and speed of acceptance is much greater and much faster.
We know that the heterogeneity of tumors is very strong. Even the appearance of tumors that look very similar may have different genetic variations, and pathology is often powerless. Moreover, the heterogeneity of tumors is also an important reason for the lack of targeted and failed new drug development.
Recently, Nature magazine published an article in which more than 100 scientists jointly developed a set of artificial intelligence based on the DNA methylation of tumors in the central nervous system for disease diagnosis and classification, which is comparable to the standard diagnostic methods. More importantly, because it is entirely based on different perspectives, this set of artificial intelligence can also find unclassified types of tumors in current medical guidelines, providing important information for the precise treatment of tumors and the development of new drugs.
Third, can artificial intelligence subvert new drug research and development?
Compared with medical imaging diagnostics, the biggest feature of new drug development is that people are always in a state of no clue. If there are drug development-related new technologies, big money makers will certainly be willing to give it a try. But can these new technologies bring about a revolutionary increase in the success rate of new drug development?
On the whole, it is regrettable that it is basically not. In part, certain technologies can indeed play an important role in speeding up the drug R&D. For example, high-throughput screening and computer-assisted drugs that have entered the drug development for many years. The "disruptive" technology that molecular design has been waiting for.
The reason is that the largest pit of new drug development is biology. The entire drug development process is the process of verifying the biological function of a target in the human body. The pits that really need to be filled are the lack of quality targets, poor clinical conversion and heterogeneity of animal models. The inherent complexity of biological systems is doomed to be a difficult problem to solve. Therefore, artificial intelligence in various multimedia ports is omnipotent, and the praises of “enhancing the success rate of research and development of new drugs and triggering the pharmaceutical revolution” are always vigilant. When the bubble bursts, the higher the number of flights, the greater the decline.
First, can artificial intelligence predict that a compound can become a drug? This answer is likely to be negative, because deep learning relies on high-quality, marked large data sets. At present, there are only about 1600 new drugs approved by the FDA (Nat Rev Drug Discov. 2017; 16(1): 19-34), far from being big data. However, similar drugs such as Eteplirsen for pseudo-dystrophic muscular dystrophy (DMD) can also be labeled as successful new drugs.
At the same time, countless compounds that fall on the road cannot be said to have no chance of becoming new medicines. If you can find suitable people and indications, you can also attach the Crown to the beads of the Bohai Sea. From this point of view, we did not understand what kind of compound we regarded as drugs. We couldn't give a clear definition of penalty points.
Compared with board games or imaging diagnostics, new drug development rules are not clear, data is unclear or even contains incorrect information, and it is full of high degree of uncertainty, which brings a huge amount of deep learning artificial intelligence based on high quality identification data sets. The challenge.
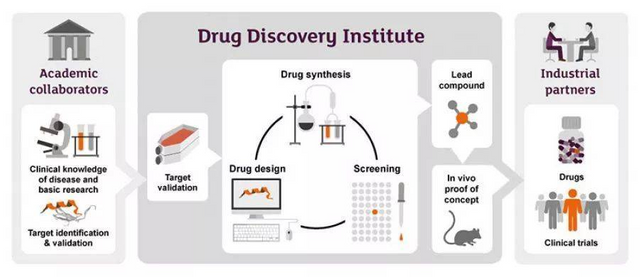
Second, how does artificial intelligence perform at all stages of drug development? The research and development of new drugs is a systematic project, from the discovery and verification of target sites, to the discovery and optimization of lead compounds, to the selection and development of candidate compounds, and finally to clinical research. It can be described as a nine-death life.
At present, artificial intelligence is indeed bustling in various fields of new drug development. Many large pharmaceutical companies have begun to cooperate with artificial intelligence startups: AstraZeneca and Berg, Johnson & Johnson and Benevolent AI, Genentech and GNS Healthcare, Merck & Atomwise, Takeda Pharmaceutical and Numerate, Sanofi, GSK and Exscientia, Pfizer and IBM Watson, etc., also have different focuses of cooperation, but mainly focused on the discovery and verification of targets including the discovery of biomarkers (how to understand The discovery and optimization of disease and lead compounds (how to design drugs) are two areas.
Fourth, the application of artificial intelligence in the discovery of new mechanisms and new targets
At present, the common problem is the use of artificial intelligence to analyze mass literature, patents, and clinical outcomes to identify potential, neglected pathways, proteins, and mechanisms, and their relevance to disease, and thus propose new hypotheses that can be tested to anticipate Discover new mechanisms and new targets. The importance of drug targets for the entire new drug R&D project is self-evident, such as how much cholesterol ester transporter (CETP) is released, sand and horse hides, and the final “samurai”, Merck, is still dying; PD- 1 How many people are ecstatic and rushing, driving the rapid growth of the entire field of biological macromolecules.
The current lack of quality targets for new drug development is well-known fact. Once a new clinically validated target has emerged, it is not uncommon for the successors of the pyramid type, and the companies at the top of the target are also highly valued. Can't climb. In the embarrassing situation of the pharmaceutical industry, the emergence of artificial intelligence seeking new mechanisms for new targets has naturally become a life-saving driftwood in the vast sea. It has gained popularity and has spawned many biotechnology companies.
Berg's Interrogative Biology platform technology based on artificial intelligence finds new targets for the treatment of diseases and biomarkers for diagnosing diseases by analyzing large numbers of patients and normal human samples (such as protein interaction networks); GTS Healthcare Analyzes massive amounts of human brain based REFS technology Biomedical and health insurance data, recommending the most appropriate treatment and drugs for patients; IBM Watson's new drug discovery system generates new hypotheses to promote new drug R&D by analyzing the massive literature for potential relevance; The American company Engine Biosciences also uses its artificial intelligence technology for new drug use, new target development, and precision medical care.
But is artificial intelligence better than current excellent biologists?
But think about it. Most of the progress made is in preclinical data. The results of the study were not published or published on a non-peer-reviewed website. Instead, a Phase 2b proof-of-concept trial was applied based on the predicted results of the new drugs. It's not a strange thing. Through experimental screening, even the occasional clinical observation of the old drugs found numerous examples. As for the article on FGF and vascular development, there is no mention of much AI content, more like traditional transcriptomics (RNA-seq) analysis plus GO enrichment analysis (of course, it may be limited to the length of the article without disclosure Artificial intelligence details).
But the biological system itself is very complicated, and the traditional methods before artificial intelligence are also similarly bumped. There is no doubt that artificial intelligence can help biologists to generate new hypotheses, but whether it will be a better hypothesis still faces great challenges.
First, the recent Nature Reviews Drug Discovery has counted 667 target numbers for FDA-approved 1578 drugs and 4479 potential drug targets for Ensembl. Of course, there are other estimates of target number. There are differences in the values, but they are far larger than the targets of currently available drugs. What's more, there are often promising new targets in each phase of CNS articles. These potential new targets are more or less obvious- Data support, not just the hidden-data that artificial intelligence finds.
How much confidence do we have to spend enough resources to validate these new targets that Natural Intelligence looks for with significant-data support? How confident can we be to spend enough resources to validate new targets with hidden-data support that artificial intelligence seeks?
Second, the benefits of artificial intelligence trained in big data lie in the fact that there are questions and answers. The downside is that there must be answers. By learning a large amount of literature data, artificial intelligence can certainly find a lot of relevance, no matter how strong or weak, but how is the signal-to-noise ratio? The biological system is complex and anomalous, with countless independent variables. Is the number of deep learning neural network layers adequate? More importantly, the massive literature must be of uneven quality, and there are quite a lot of wrong information and conclusions, non-repeatable experimental data and conclusions, some open experimental data and conclusions, plausible experimental data and conclusions, intentionally or unintentionally misleading. Sexual experimental data and conclusions, blindly chasing hot spots lead to experimental data and conclusions related to the addition of points. The author believes that the above-mentioned circumstances, people in the industry must have a deep understanding.
Based on such data sets, how should artificial intelligence learn? An excellent researcher also needs many years of training to learn to distinguish reliable or unreliable information from the literature. This implies a great deal of logical reasoning and common sense, and even occasionally involves the evaluation of the author’s academic reputation. It is not an area where artificial intelligence is good at.
Furthermore, we all know that relevance, even strong correlation, is not causal. For example, the genomic association analysis (GWAS) often tells us that certain genes are strongly related to certain diseases. However, these genes are still away from becoming a drug target and are still away from the tens of thousands of miles. It takes scientists to explore and verify this step by step. The relationship between genes and diseases, to understand the specific mechanism mechanism is likely to enter the eyes of new drug developers, this shake may have passed over 10 years. The start-up of a new drug R&D project means a lot of investment in capital and manpower, so the drug targets that can really enter the drug development pipeline are carefully selected and rigorously validated. The so-called AI weak water 3000, NI only take a scoop.
However, although the biological system is extremely complex, if it is restored to a simpler level, such as the cellular level, combined with the powerful image learning ability of artificial intelligence, it is expected to achieve a breakthrough. Researchers from companies and schools such as Janssen used traditional high-throughput screening of cell models for glucocorticoid receptors, screened 500,000 compounds, obtained cell phenotype image data for compounds, and generated image-based molecular fingerprints. At the same time combining the biological activity of these compounds previously determined in a screening model of more than 500 different targets as a training set, an artificial intelligence model is trained using deep learning methods, which can then be based on compounds at the glucocorticoid receptor cell sheet. Type image data to predict biological activity data of compounds against other unrelated targets.
This means that a single high-throughput cell phenotype image screening model can replace many time-consuming and labor-intensive screening models for specific targets and pathways, significantly reducing labor and time costs. At the same time, Cell Image Library provided tens of thousands of compound-treated cells with different image and morphological data for artificial intelligence learning in order to find new mechanisms for drug action. The authors speculate whether this research will lead to the emergence of an emerging discipline, Imagenome, combined with data from other studies of histology, and be used synthetically to study the molecular mechanisms of phenotypic changes at the cellular level.
In general, artificial intelligence based on big data excels at the excavation, reorganization, and distribution of existing knowledge, so artificial intelligence can learn existing diagnostic imaging rules and can even see it more quickly and quickly. The vast amount of data to find the relevance of existing knowledge. But every time the new drug's R&D success is achieved, human beings break through the existing knowledge framework and make new breakthroughs in disease awareness.
The emergence of new knowledge comes from numerous trials and errors of human beings and practices, rather than a line drawn from existing knowledge. Whether you can better understand the disease, I believe that to see the reader here, already have their own judgments. Can it produce drug candidates on a scale? Is it "Garbage quick in, Garbage quick out" or is there another hole?