Increase 12 times!HKBU and MassGrid Publish New AI Training Algorithms with Low Bandwidth and High Efficiency
 In terms of scaling efficiency, we evaluate gTop-k on a cluster with 32 GPU machines which are interconnected with 1 Gbps Ethernet. The experimental results show that our method achieves 2.7−12× higher scaling efficiency than S-SGD and 1.1−1.7× improvement than the existing Top-k S-SGD.
In terms of scaling efficiency, we evaluate gTop-k on a cluster with 32 GPU machines which are interconnected with 1 Gbps Ethernet. The experimental results show that our method achieves 2.7−12× higher scaling efficiency than S-SGD and 1.1−1.7× improvement than the existing Top-k S-SGD.
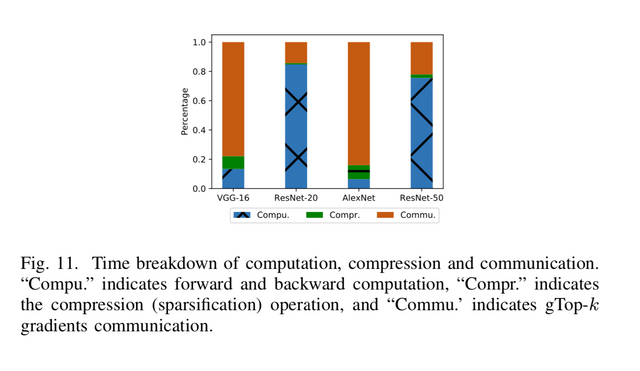
Distributed synchronous stochastic gradient descent (S-SGD) has been widely used in training large-scale deep neural networks (DNNs), but it typically requires very high communication bandwidth between computational workers (e.g., GPUs) to exchange gradients iteratively. Recently, Top-k sparsification techniques have been proposed to reduce the volume of data to be exchanged among workers. Top-k sparsification can zero-out a significant portion of gradients without impacting the model convergence. However, the sparse gradients should be transferred with their irregular indices, which makes the sparse gradients aggregation difficult. Current methods that use AllGather to accumulate the sparse gradients have a communication complexity of O(kP), where P is the number of workers, which is inefficient on low bandwidth networks with a large number of workers. We observe that not all top-k gradients from P workers are needed for the model update, and therefore we propose a novel global Top-k (gTop-k) sparsification mechanism to address the problem. Specifically, we choose global top-k largest absolute values of gradients from P workers, instead of accumulating all local top-k gradients to update the model in each iteration. The gradient aggregation method based on gTop-k sparsification reduces the communication complexity from O(kP) to O(klogP). Through extensive experiments on different DNNs, we verify that gTop-k S-SGD has nearly consistent convergence performance with S-SGD, and it has only slight degradations on generalization performance. In terms of scaling efficiency, we evaluate gTop-k on a cluster with 32 GPU machines which are interconnected with 1 Gbps Ethernet. The experimental results show that our method achieves 2.7−12× higher scaling efficiency than S-SGD and 1.1−1.7× improvement than the existing Top-k S-SGD.
Paper link:https://arxiv.org/abs/1901.04359
PDF:https://arxiv.org/pdf/1901.04359.pdf
join us to know more about machine learning and massgrid network.