[Tutorial for steemr] Retrieving and Analyzing the Comment Data
Repository
https://github.com/pzhaonet/steemr
What Will I Learn?
- Using the function
gcomment()to retrieve the comment data of a given ID. - Using other R functions to enhance and analyze the data retrieved by
gcomment().
Requirements
- Windows/mac/Linux OS
- R environment
- R steemr package
- RStudio IDE (recommended)
Difficulty
- Intermediate
Basic usage of gcomments()
Load the 'steemr' package:
require('steemr')
## Loading required package: steemr
The function name 'gcomment' means 'get comment data'. It is very easy to get the comments of a given ID if you have a SteemSQL user name and password.
Firstly, use the ssql() function to build a connection to SteemSQL:
mysql <- ssql(uid = your_steemsql_id, pwd = your_steemsql_password)
You have to replace your_steemsql_id and your_steemsql_password with your own.
Then, use the gcomments() function to retrieve the newest comment data of the given ID. Let's retrieve @dapeng's newest comments:
mycmt <- gcomments(id = 'dapeng', sql_con = mysql)
'mycmt' is a list with 2 elements, which are 'comment' and 'daily':
length(mycmt)
## [1] 2
names(mycmt)
## [1] "comment" "daily"
Both of them are data frames. Have a look at what columns they have:
names(mycmt$comment)
## [1] "root_title" "root_comment" "created" "body"
## [5] "date"
names(mycmt$daily)
## [1] "date" "Freq"
The 'daily' dataframe is a summary, showing how many comments every day. Let's see what it is:
mycmt$daily
## date Freq
## 1 2018-06-30 4
## 2 2018-07-01 15
## 3 2018-07-02 10
## 4 2018-07-03 12
## 5 2018-07-04 5
## 6 2018-07-05 25
## 7 2018-07-06 3
We can view 'comment' by running:
View(mycmt$comment)
In the topleft panel, a spread sheet appears on the tab 'mycmt$comment'. We can order or filter each column:
By default, gcomments() retrieves the comments in the last 7 days.
Exercise 1: Get the comment records of your own or someone of interest. On which day did he/she post the most comments?
Advanced usage of gcomments()
Let's go further into gcomments().
Multiple parameters are available for gcomments():
idspecifies the ID of interest, which is mandatory.fromandtospecifies the date range of the target comments. The date must be given in 'year-month-day' format.selectspecifies the columns to retrieve. By default, it queries four columns from the server: "root_title", "root_comment", "created", and "body".select = '*'retrieves all the columns. We will give an example.sql_conbuilds a connection to SteemSQL server.if_plotspecifies whether to plot the daily comment number.ylabspecifies the label of the y axis. It is valid only when if_plot is TRUE.
Now let's query the @dapeng's comments from the beginning of 2016 and make a plot of the daily comment number.
mycmt_all <- gcomments(id = 'dapeng',
sql_con = mysql,
from = '2016-10-01',
if_plot = TRUE)
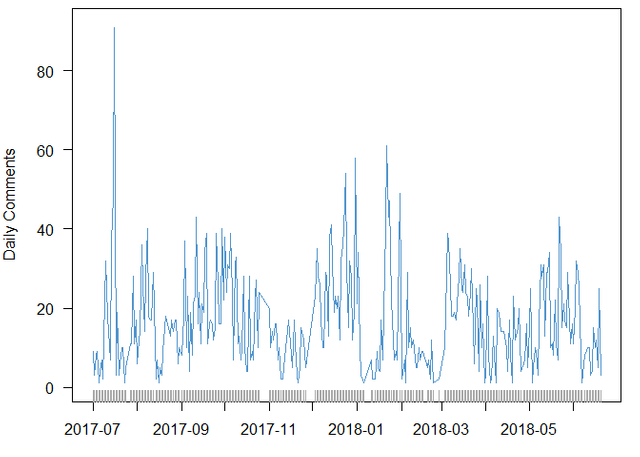
Right. @dapeng did not post any comment until the summer 2017.
nrow(mycmt_all$comment)
## [1] 5359
He wrote 5359 comments in total.
Let's get the full information with all the columns of @dapeng's comments, and see what columns we can get.
mycmt_full <- gcomments(id = 'dapeng',
sql_con = mysql,
select = '*',
from = '2016-10-01')
names(mycmt_full$comment)
## [1] "ID" "author"
## [3] "permlink" "category"
## [5] "parent_author" "parent_permlink"
## [7] "title" "body"
## [9] "json_metadata" "last_update"
## [11] "created" "active"
## [13] "last_payout" "depth"
## [15] "children" "net_rshares"
## [17] "abs_rshares" "vote_rshares"
## [19] "children_abs_rshares" "cashout_time"
## [21] "max_cashout_time" "total_vote_weight"
## [23] "reward_weight" "total_payout_value"
## [25] "curator_payout_value" "author_rewards"
## [27] "net_votes" "root_comment"
## [29] "mode" "max_accepted_payout"
## [31] "percent_steem_dollars" "allow_replies"
## [33] "allow_votes" "allow_curation_rewards"
## [35] "beneficiaries" "url"
## [37] "root_title" "pending_payout_value"
## [39] "total_pending_payout_value" "active_votes"
## [41] "replies" "author_reputation"
## [43] "promoted" "body_length"
## [45] "reblogged_by" "body_language"
## [47] "TS" "date"
Exercise 2: Plot the daily comment number of an ID of your interest.
Analysis of the data by gcomments(): Examples
With the data retrieved via gcomments(), we could produce a summary report:
summary(mycmt_all$daily)
## date Freq
## Min. :2017-07-17 Min. : 1.00
## 1st Qu.:2017-10-08 1st Qu.: 8.00
## Median :2018-01-09 Median :14.00
## Mean :2018-01-10 Mean :16.75
## 3rd Qu.:2018-04-15 3rd Qu.:24.00
## Max. :2018-07-06 Max. :91.00
It could be found that @dapeng left his first comment on 2017-07-17. Averagely he wrote 14 comments per day. On the busiest day he wrote 91 comments. Which day was it?
mycmt_all$daily$date[which.max(mycmt_all$daily$Freq)]
## [1] "2017-08-01"
He does not remember why.
Was he so lazy that he repeated the same comment? We could use the duplicated() function to see if he has repeated comments.
sum(duplicated(mycmt_all$comment$body))
## [1] 296
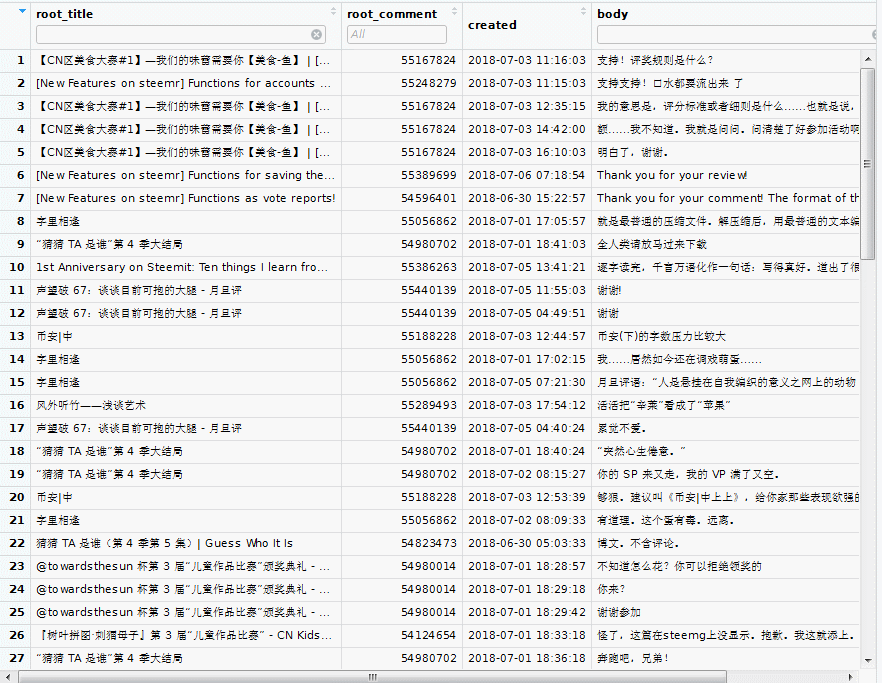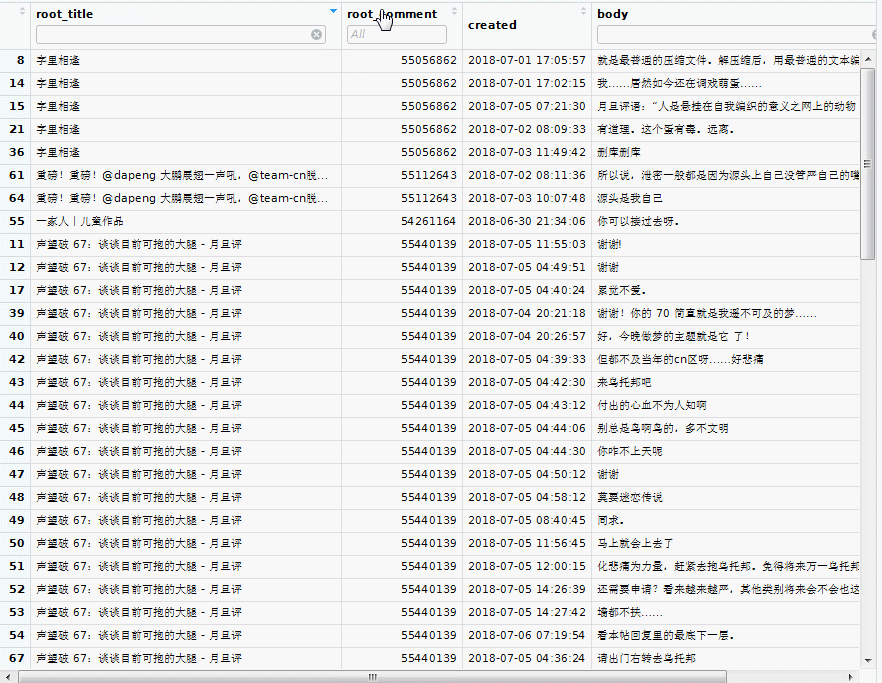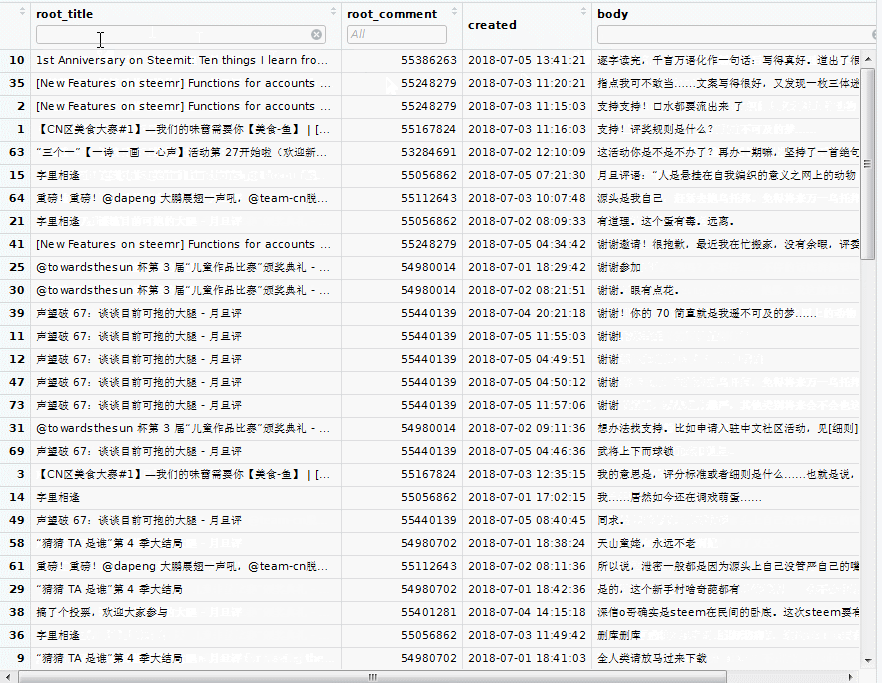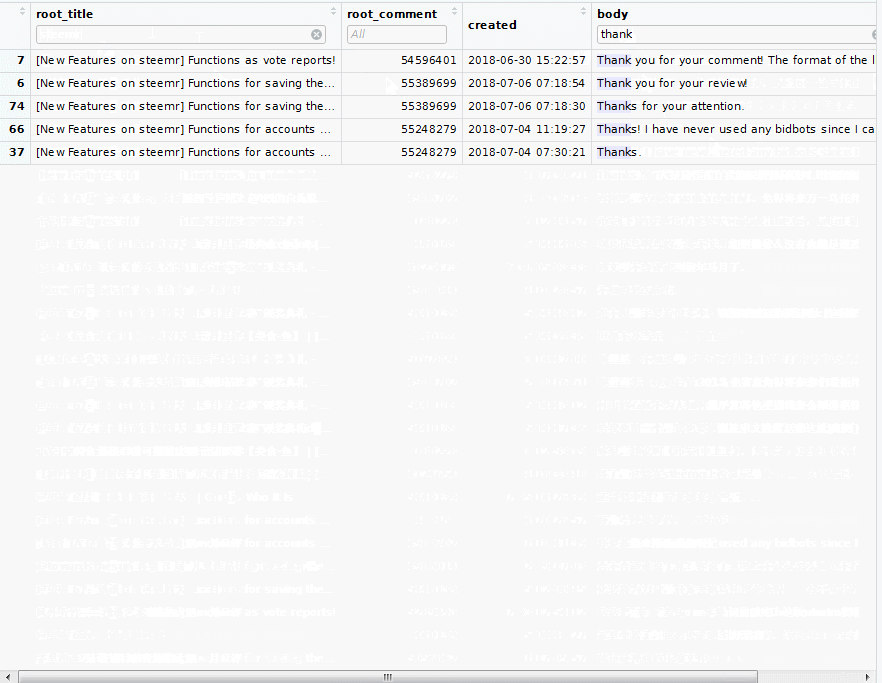
He had 296 duplicated comments! What were they? We can use the table() function to count the frequency of each duplicated comments, and order them descendingly.
mytab <- as.data.frame(table(mycmt_all$comment$body))
mytab <- mytab[order(-mytab$Freq), ]
Then let's see the top 6 duplicated comments and their frequency:
head(mytab)
## Var1 Freq
## 401 Thank you! 51
## 470 Thanks! 35
## 3936 谢谢! 29
## 1 18
## 483 Thanks. 13
## 3931 谢谢 13
There seemed 18 blank comments, which means he deleted them. The rest are the English and Chinese version of 'thanks'. It cannot be wrong if you repeat saying thanks, can it?
Exercise 3: analyze the comment data you have got.
Proof of Work Done
The manuscript and the code used in this tutorial can be found in:
https://github.com/pzhaonet/steemr-book
Hey @dapeng
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Thank you for your contribution.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
WARNING! The comment below by @erudire leads to a known phishing site that could steal your account.
Do not open links from users you do not trust. Do not provide your private keys to any third party websites.
我发现我被某人排除出了关注队列,然后又加回来了😂
🍭
🍓
🍰
好多甜食,有点牙疼
🍰🍭🍦🍬🥧🍧🍯🥤🍼🍪🌰
Free Upvotes

ENJOY !
http://toolsfree.info/votes/