Data Structures And Algorithms | 2019-07-02
Data Structures And Algorithms
Detecting Feedback Vertex Sets of Size 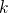 in
in 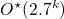 Time (1906.12298v1)
Time (1906.12298v1)
Jason Li, Jesper Nederlof
2019-06-28
In the Feedback Vertex Set problem, one is given an undirected graph
and an integer
in run times of the type
, where the
notation omits factors polynomial in
. This race seemed to be run in 2011, when a randomized algorithm
time algorithm based on Cut&Count was introduced. In this work, we show the contrary and give a
can be found in polynomial time. Second, we give a randomized branching strategy inspired by the one from~[Becker et al. (J. Artif. Intell. Res'00)] to reduce to the aforementioned bounded average degree setting. Third, we obtain significant run time improvements by employing fast matrix multiplication.
A  -Competitive Algorithm for Scheduling Packets with Deadlines (1807.07177v4)
-Competitive Algorithm for Scheduling Packets with Deadlines (1807.07177v4)
Pavel Veselý, Marek Chrobak, Łukasz Jeż, Jiří Sgall
2018-07-18
In the online packet scheduling problem with deadlines (PacketScheduling, for short), the goal is to schedule transmissions of packets that arrive over time in a network switch and need to be sent across a link. Each packet has a deadline, representing its urgency, and a non-negative weight, that represents its priority. Only one packet can be transmitted in any time slot, so, if the system is overloaded, some packets will inevitably miss their deadlines and be dropped. In this scenario, the natural objective is to compute a transmission schedule that maximizes the total weight of packets which are successfully transmitted. The problem is inherently online, with the scheduling decisions made without the knowledge of future packet arrivals. The central problem concerning PacketScheduling, that has been a subject of intensive study since 2001, is to determine the optimal competitive ratio of online algorithms, namely the worst-case ratio between the optimum total weight of a schedule (computed by an offline algorithm) and the weight of a schedule computed by a (deterministic) online algorithm. We solve this open problem by presenting a
-competitive online algorithm for PacketScheduling (where
is the golden ratio), matching the previously established lower bound.
Improving and benchmarking of algorithms for decision making with lower previsions (1906.12215v1)
Nawapon Nakharutai, Matthias C. M. Troffaes, Camila C. S. Caiado
2019-06-28
Maximality, interval dominance, and E-admissibility are three well-known criteria for decision making under severe uncertainty using lower previsions. We present a new fast algorithm for finding maximal gambles. We compare its performance to existing algorithms, one proposed by Troffaes and Hable (2014), and one by Jansen, Augustin, and Schollmeyer (2017). To do so, we develop a new method for generating random decision problems with pre-specified ratios of maximal and interval dominant gambles. Based on earlier work, we present efficient ways to find common feasible starting points in these algorithms. We then exploit these feasible starting points to develop early stopping criteria for the primal-dual interior point method, further improving efficiency. We find that the primal-dual interior point method works best. We also investigate the use of interval dominance to eliminate non-maximal gambles. This can make the problem smaller, and we observe that this benefits Jansen et al.'s algorithm, but perhaps surprisingly, not the other two algorithms. We find that our algorithm, without using interval dominance, outperforms all other algorithms in all scenarios in our benchmarking.
PUFFINN: Parameterless and Universally Fast FInding of Nearest Neighbors (1906.12211v1)
Martin Aumüller, Tobias Christiani, Rasmus Pagh, Michael Vesterli
2019-06-28
We present PUFFINN, a parameterless LSH-based index for solving the
Generating Normal Networks via Leaf Insertion and Nearest Neighbor Interchange (1906.12053v1)
Louxin Zhang
2019-06-28
Galled trees are studied as a recombination model in theoretic population genetics. This class of phylogenetic networks has been generalized to tree-child networks, normal networks and tree-based networks by relaxing a structural condition. Although these networks are simple, their topological structures have yet to be fully understood. It is well-known that all phylogenetic trees on
taxa. We prove that all tree-child networks with
or
The Moser-Tardos Framework with Partial Resampling (1406.5943v5)
David G. Harris, Aravind Srinivasan
2014-06-23
The resampling algorithm of Moser & Tardos is a powerful approach to develop constructive versions of the Lov'{a}sz Local Lemma (LLL). We generalize this to partial resampling: when a bad event holds, we resample an appropriately-random subset of the variables that define this event, rather than the entire set as in Moser & Tardos. This is particularly useful when the bad events are determined by sums of random variables. This leads to several improved algorithmic applications in scheduling, graph transversals, packet routing etc. For instance, we settle a conjecture of Szab'{o} & Tardos (2006) on graph transversals asymptotically, and obtain improved approximation ratios for a packet routing problem of Leighton, Maggs, & Rao (1994).
Near-Optimal Methods for Minimizing Star-Convex Functions and Beyond (1906.11985v1)
Oliver Hinder, Aaron Sidford, Nimit Sharad Sohoni
2019-06-27
In this paper, we provide near-optimal accelerated first-order methods for minimizing a broad class of smooth nonconvex functions that are strictly unimodal on all lines through a minimizer. This function class, which we call the class of smooth quasar-convex functions, is parameterized by a constant
, where
encompasses the classes of smooth convex and star-convex functions, and smaller values of
indicate that the function can be "more nonconvex." We develop a variant of accelerated gradient descent that computes an
-approximate minimizer of a smooth
total function and gradient evaluations. We also derive a lower bound of
on the number of gradient evaluations required by any deterministic first-order method in the worst case, showing that, up to a logarithmic factor, no deterministic first-order algorithm can improve upon ours.
Faster and Better Nested Dissection Orders for Customizable Contraction Hierarchies (1906.11811v1)
Lars Gottesbüren, Michael Hamann, Tim Niklas Uhl, Dorothea Wagner
2019-06-27
Graph partitioning has many applications. We consider the acceleration of shortest path queries in road networks using Customizable Contraction Hierarchies (CCH). It is based on computing a nested dissection order by recursively dividing the road network into parts. Recently, with FlowCutter and Inertial Flow, two flow-based graph bipartitioning algorithms have been proposed for road networks. While FlowCutter achieves high-quality results and thus fast query times, it is rather slow. Inertial Flow is particularly fast due to the use of geographical information while still achieving acceptable quality. We combine the techniques of both algorithms to achieve more than six times faster preprocessing times than FlowCutter and even slightly better quality. We show that using 16 cores of a shared-memory machine, this preprocessing needs four minutes on the Europe road network.
A Constant-Factor Approximation Algorithm for Online Coverage Path Planning with Energy Constraint (1906.11750v1)
Ayan Dutta, Gokarna Sharma
2019-06-27
In this paper, we study the problem of coverage planning by a mobile robot with a limited energy budget. The objective of the robot is to cover every point in the environment while minimizing the traveled path length. The environment is initially unknown to the robot. Therefore, it needs to avoid the obstacles in the environment on-the-fly during the exploration. As the robot has a specific energy budget, it might not be able to cover the complete environment in one traversal. Instead, it will need to visit a static charging station periodically in order to recharge its energy. To solve the stated problem, we propose a budgeted depth-first search (DFS)-based exploration strategy that helps the robot to cover any unknown planar environment while bounding the maximum path length to a constant-factor of the shortest-possible path length. Our
-approximation guarantee advances the state-of-the-art of log-approximation for this problem. Simulation results show that our proposed algorithm outperforms the current state-of-the-art algorithm both in terms of the traveled path length and run time in all the tested environments with concave and convex obstacles.
A note on the Split to Block Vertex Deletion problem (1906.10012v2)
Dekel Tsur
2019-06-24
In the Split to Block Vertex Deletion (SBVD) problem the input is a split graph
of at most
is a block graph. In this paper we give an algorithm for SBVD whose running time is
.