Data Structures And Algorithms | 2019-07-18
Data Structures And Algorithms
Fast, Provably convergent IRLS Algorithm for p-norm Linear Regression (1907.07167v1)
Deeksha Adil, Richard Peng, Sushant Sachdeva
2019-07-16
Linear regression in
-norm is a canonical optimization problem that arises in several applications, including sparse recovery, semi-supervised learning, and signal processing. Generic convex optimization algorithms for solving
Our algorithm is simple to implement and is guaranteed to find a
-approximate solution in
iterations. Our experiments demonstrate that it performs even better than our theoretical bounds, beats the standard Matlab/CVX implementation for solving these problems by 10--50x, and is the fastest among available implementations in the high-accuracy regime.
A Faster Algorithm for Cuckoo Insertion and Bipartite Matching in Large Graphs (1611.07786v2)
Megha Khosla, Avishek Anand
2016-11-23
Hash tables are ubiquitous in computer science for efficient access to large datasets. However, there is always a need for approaches that offer compact memory utilisation without substantial degradation of lookup performance. Cuckoo hashing is an efficient technique of creating hash tables with high space utilisation and offer a guaranteed constant access time. We are given
locations and
items. Each item has to be placed in one of the
locations chosen by
random hash functions. By allowing more than one choice for a single item, cuckoo hashing resembles multiple choice allocations schemes. In addition it supports dynamically changing the location of an item among its possible locations. We propose and analyse an insertion algorithm for cuckoo hashing that runs in \emph{linear time} with high probability and in expectation. Previous work on total allocation time has analysed breadth first search, and it was shown to be linear only in \emph{expectation}. Our algorithm finds an assignment (with probability 1) whenever it exists. In contrast, the other known insertion method, known as \emph{random walk insertion}, may run indefinitely even for a solvable instance. We also present experimental results comparing the performance of our algorithm with the random walk method, also for the case when each location can hold more than one item. As a corollary we obtain a linear time algorithm (with high probability and in expectation) for finding perfect matchings in a special class of sparse random bipartite graphs. We support this by performing experiments on a real world large dataset for finding maximum matchings in general large bipartite graphs. We report an order of magnitude improvement in the running time as compared to the \emph{Hopkraft-Karp} matching algorithm.
Step-by-Step Community Detection for Volume-Regular Graphs (1907.07149v1)
Luca Becchetti, Emilio Cruciani, Francesco Pasquale, Sara Rizzo
2019-07-16
Spectral techniques have proved amongst the most effective approaches to graph clustering. However, in general they require explicit computation of the main eigenvectors of a suitable matrix (usually the Laplacian matrix of the graph). Recent work (e.g., Becchetti et al., SODA 2017) suggests that observing the temporal evolution of the power method applied to an initial random vector may, at least in some cases, provide enough information on the space spanned by the first two eigenvectors, so as to allow recovery of a hidden partition without explicit eigenvector computations. While the results of Becchetti et al. apply to perfectly balanced partitions and/or graphs that exhibit very strong forms of regularity, we extend their approach to graphs containing a hidden
A tight kernel for computing the tree bisection and reconnection distance between two phylogenetic trees (1811.06892v2)
Steven Kelk, Simone Linz
2018-11-16
In 2001 Allen and Steel showed that, if subtree and chain reduction rules have been applied to two unrooted phylogenetic trees, the reduced trees will have at most 28k taxa where k is the TBR (Tree Bisection and Reconnection) distance between the two trees. Here we reanalyse Allen and Steel's kernelization algorithm and prove that the reduced instances will in fact have at most 15k-9 taxa. Moreover we show, by describing a family of instances which have exactly 15k-9 taxa after reduction, that this new bound is tight. These instances also have no common clusters, showing that a third commonly-encountered reduction rule, the cluster reduction, cannot further reduce the size of the kernel in the worst case. To achieve these results we introduce and use "unrooted generators" which are analogues of rooted structures that have appeared earlier in the phylogenetic networks literature. Using similar argumentation we show that, for the minimum hybridization problem on two rooted trees, 9k-2 is a tight bound (when subtree and chain reduction rules have been applied) and 9k-4 is a tight bound (when, additionally, the cluster reduction has been applied) on the number of taxa, where k is the hybridization number of the two trees.
Finding a latent k-polytope in O(k . nnz(data)) time via Subset Smoothing (1904.06738v3)
Chiranjib Bhattacharyya, Ravindran Kannan
2019-04-14
In this paper we show that a large class of Latent variable models, such as Mixed Membership Stochastic Block(MMSB) Models, Topic Models, and Adversarial Clustering, can be unified through a geometric perspective, replacing model specific assumptions and algorithms for individual models. The geometric perspective leads to the formulation: \emph{find a latent
polytope
in
given
matching the best running time of algorithms in special cases considered here and is better when the data is sparse, as is the case in applications. An important novelty of the algorithm is the introduction of \emph{subset smoothed polytope},
, the convex hull of the
points obtained by averaging all
subsets of the data points, for a given
. We show that
, (b) Adversarial Clustering: In
On The Termination of a Flooding Process (1907.07078v1)
Walter Hussak, Amitabh Trehan
2019-07-16
Flooding is among the simplest and most fundamental of all distributed network algorithms. A node begins the process by sending a message to all its neighbours and the neighbours, in the next round forward the message to all the neighbours they did not receive the message from and so on. We assume that the nodes do not keep a record of the flooding event. We call this amnesiac flooding (AF). Since the node forgets, if the message is received again in subsequent rounds, it will be forwarded again raising the possibility that the message may be circulated infinitely even on a finite graph. As far as we know, the question of termination for such a flooding process has not been settled - rather, non-termination is implicitly assumed. In this paper, we show that synchronous AF always terminates on any arbitrary finite graph and derive exact termination times which differ sharply in bipartite and non-bipartite graphs. Let
be a finite connected graph. We show that synchronous AF from a single source node terminates on
rounds, where
rounds where
and
is the diameter of
for bipartite and non-bipartite graphs respectively. If communication/broadcast to all nodes is the motivation, our results show that AF is asymptotically time optimal and obviates the need for construction and maintenance of spanning structures like spanning trees. The clear separation in the termination times of bipartite and non-bipartite graphs also suggests mechanisms for distributed discovery of the topology/distances in arbitrary graphs. For comparison, we show that, in asynchronous networks, an adaptive adversary can force AF to be non-terminating.
A spectral bound on hypergraph discrepancy (1907.04117v2)
Aditya Potukuchi
2019-07-07
Let
be a
-regular hypergraph on
be the
incidence matrix of
. We show that the discrepancy of
. As a corollary, this gives us that for every
edges is almost surely
as
Lossless Prioritized Embeddings (1907.06983v1)
Michael Elkin, Ofer Neiman
2019-07-16
Given metric spaces
and
and an ordering
of
is said to have a prioritized distortion
, if for any pair
of distinct points in
, the distortion provided by
for this pair is at most
. If
is a normed space, the embedding is said to have prioritized dimension
, if
may have nonzero entries only in its first
coordinates. The notion of prioritized embedding was introduced by \cite{EFN15}, where a general methodology for constructing such embeddings was developed. Though this methodology enables \cite{EFN15} to come up with many prioritized embeddings, it typically incurs some loss in the distortion. This loss is problematic for isometric embeddings. It is also troublesome for Matousek's embedding of general metrics into
, which for a parameter
, provides distortion
and dimension
. In this paper we devise two lossless prioritized embeddings. The first one is an isometric prioritized embedding of tree metrics into
. The second one is a prioritized Matousek's embedding of general metrics into
and dimension
A Turing Kernelization Dichotomy for Structural Parameterizations of 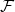 -Minor-Free Deletion (1906.05565v2)
-Minor-Free Deletion (1906.05565v2)
Huib Donkers, Bart M. P. Jansen
2019-06-13
For a fixed finite family of graphs
and asks whether there exists a set
of size at most
is
and
this encodes Vertex Cover and Feedback Vertex Set respectively. When parameterized by the feedback vertex number of
. This rules out the existence of a polynomial kernel assuming
, and also gives evidence that the problem does not admit a polynomial Turing kernel. Our hardness result generalizes to any
-subgraph-free graph, using as parameter the vertex-deletion distance to treewidth
, where
Labelings vs. Embeddings: On Distributed Representations of Distances (1907.06857v1)
Arnold Filtser, Lee-Ad Gottlieb, Robert Krauthgamer
2019-07-16
We investigate for which metric spaces the performance of distance labeling and of
is assigned a succinct label, such that the distance between any two points
can be approximated given only their labels. A highly structured special case is an embedding into
such that
is approximately
. The performance of a distance labeling or an
of the point set
if every
has label size at most
has prioritized dimension