实验模型合理是实验成败的关键
任何一款新产品,从概念变成现实,都必须有一个制造系统。 实际地制造出样品,使达到预期的性能指标,必须经历一个开发过程。 这个开发过程,按照日本学者田口玄一的思想, 需要经历系统设计,参数设计,容差设计过程,称为三次设计。 美国学者则把概念设计本身包含在开发过程之内,开发过程分为四步。
实验的目的,是实现产品的性能。假设有q 种性能指标,用响应变量 Y 来表达, 可以用向量简记作 Y=(y1,y2,...,yq)。 制造系统包括 装置流程,配方和工艺方法,包含许许多多变量,有定性的,有定量的。 假设用 p 个变量表达。 用向量可以写成 X=(x1,x2,...,xp)。
制造系统如何产生?xi 从哪里来?来自我们对产品概念的理解, 对制造过程的机理和运行机制的认识。 也可以称为指导思想,猜想着如何如何就可以把所要的产品制造出来。 实验科学称这些为实验模型或系统模型,我们简单地记作 M 。 按照这个模型设计制造系统。意味着,设计者认为,给定 X 就可以得到 Y。 能不能得到,另当别论。首先必须有。没有,猜也得猜一个。 实验模型就像一个盒子,盒子里面装着 M ,连接着 X 和 Y。X 经过这个盒子转变成 Y。 所以,实验设计科学称 X 为输入,Y 为输出。输入,输出是相对于盒子而言的。 Y,X 以及 M 之间的关系可以用一个图来表达,见图 1。

图 1. 实验模式示意图
实验过程能不能如愿将输入X 变成输出 Y?事前是不知道的, 哪怕是最简单的实验都未必有必定成功的把握。 因此,实验模型也是一种设计,或叫做假设,或者猜想。 这种猜想不是唯一的,同一事物可以有不同的猜想,M 也是一个变量。 因而有真伪、好坏之分。一次猜得正确不容易,所以需要试验,对各种猜想进行比较和筛选。 Y,X 以及 M ,这三样东西互相联系,共同组成一个固定模式。 不管是物理的,化学的,生物的,社会经济学的,也包括数学实验,都必须具备,缺一不可。
在实验科学中有很多著名的实验模型,例如,分子模型,原子模型,宇宙模型,大气模型,DNA模型等等。 用实验模型描述对象,把对象数字化,有利于认识和把握对象。 我们现在使用实验模型的概念主要是针对实验过程中系统局部特性而言的。 大系统有大系统的模型,大系统可以划分出许多子系统,子系统有子系统的模型。使问题较容易逐个解决。 开发过程在实验模型-系统设计-参数优化之间作三重迭代。
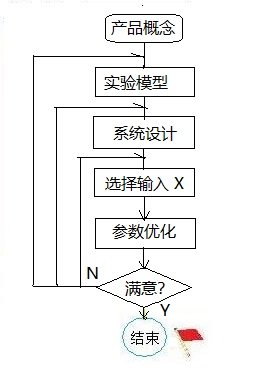
图 2. 开发过程在实验模型-系统设计-参数优化之间作三重迭代。
工业试验的试验设计就是从系统变量中选择输入变量组成 X。 有了X之后,就可以设计出不同的参数组合,成为一组实验条件。 送进 盒子, 观察其输出 Y,来分析归纳出一个经验方程,推断X,Y 之间的关系。 进而找到优化的参数组合或者找到下一步的行动策略。
统计学利用黑箱模型(过程机制完全不知道,盒子里面是黑的)研究任何两种事物之间的关系。 这个过程基于数据样本。在收集数据时不假设它们之间是什么关系,不猜测变量之间的机制。 建立各种数学模型,用统计学检验标准来决定事物之间的相关程度来作出判断。 常常出现公说公有理婆说婆有理的情况,称为不确定性。把这种方法应用于工业试验存在很多弊端。 用统计学方法来设计实验,分析实验数据,得到预报方程,利用预报方程来优化参数,指导实践。 黑箱模型需要大样本,而我们希望用最少的试验数目,最短的开发周期,最少的消耗,开发出质量最好的产品。 即我们希望由小样本得到具有较高确定性的预报方程。虽然这个预报方程也只具有经验性质, 如果能反应过程的机制,有较高的确定性岂不更好。至少我们希望它具有较高的确定性。 要做到这一点,预报方程不能不反映过程的机制,不能是完全没有根据的猜测。 因此,实验必须是有目的有计划的,要对一种猜测作出检验和判断。对过程机制不甚了解,至少应该有一个假设或者猜测。 成功了,猜测是对的。部分成功了,部分是对的。不管成功或是失败,我们都前进了一大步。 只有当我们对过程机制的认识正确或接近实际,才能正确地设计制造系统,实验会顺利成功,甚至一次成功。 如果对过程机制的理解是错误的,那么就一定不能正确地设计系统,实验就不可能顺利,难以得到好的结果。 事前对机制的认识或猜测是正确的,设计的系统也是正确的,那么,执行一次操作之后,会得到一个非空的 Y。 如果 X 是优化组合,则Y是优良的。如果 X 不是最优化的组合,则Y不会是理想的。 如果 Y非常小,即,样机没有造出来,或性能非常不满意,一定是某个环节出了问题。
实验失败有三种可能原因:
- 对过程机制的理解不正确,实验模型不合理;
- 系统设计出错;
- 参数组合不合理。
对猜想进行实验,比较判断,需要有一个公平的机制。需要大家都处在最佳的“竞技”状态。 所以,每种实验模型都应该找到它的优化点,除非已经能够作出判断,让某种模型出局。 实验的数目是 X 中变量数目 (p) 的一个简单函数。若要做显著性检验, 向后逐步回归要求误差自由度至少是 1,实验数目至少需要比参数数目多 1。这样, 线性模型的回归变量数为 p, 实验数不能少于 p+2。全实施析因模型的参数数目是 2p, 等等。 变量越多,实验数目越多,难度越大。系统设计确定之后,如何确定 X 是关键。 X 的选择属于优化过程范畴。但 X 必定来自系统。 这样,准确的猜测是多么重要。特别是第一次猜测尤为重要。第一次猜测成功有利于实验者的信心, 第一次猜测的失败会挫伤实验者的意志,瓦解团队的斗志。半成功的第一次容易固步自封,不愿意继续前进,拒绝新思想。 同样道理,课题在手,如果首先查文献,发现了文献方法,会如获至宝,拒绝思考建立自己的实验模型和系统思想。 所以作者认为,接到任务之后,第一要做的,不是查文献,而是立足了基础理论,独立思考,建立自己的实验模型,然后去查文献, 这样才不会抄袭,不会陷入文献陷阱,不会埋没自己团队的创造力。这就叫做没有框框,没有思维定势。
有一种指导,“把全部变量拿来做实验”,这种所谓的毕其功于一役的指导不可行。 系统是全局,包含的变量很多,以致一次把系统的全部变量都拿来做试验,可能连微型计算机都算不了。 研究的早期,未必能正确地认识系统找出全部影响因素。 随着开发过程的深入,会发现先前的认识的缺陷和错误,需要修改系统,修改X。 实际上,通常是根据经验和既有知识将系统的部分变量暂时固定,只让一部分变动。 以全实施析因模型为例,少一个变量,实验数目少了一半。足见减少变量数目的意义。
如果一个变量不在 X 之中,它不能进入我们的观察视野,不可能进入预报方程。 只要有一个显著变量没有放进 X 中,实验就不可能最优化。 因此,输入 X 应该包含所有对 Y 有显著影响的因子。
这里的术语“显著影响”是一个统计概念,与统计检验标准有关。 统计学上,具有95% 的置信概率,就称为“在统计学意义上是显著的”; 具有99% 的置信概率,就称为“在统计学意义上是高度显著的”。 探索性试验,对于某些实验误差很大的实验,为了不丢失“苗头”,可以放宽。门槛由实验者掌握。 统计学定义则不能随意修改,公开发表的报告必须符合这个标准。 有个化学实验收率增加 了 1% ,相对于一个措施使收率增加30%,那不算很显著。 处在不同的实验阶段,不同的基础(均值),有不同的追求。
如果一个变量对 y 没有显著的影响,经过试验和分析之后,它不应该进入预报方程之中, 如果采样方案因子之间相关性很强,就会出现例外。X 多一个变量,要付出相应试验成本。 如果能在事前作出这样的判断,这样的变量不应该放在输入 X 中,即让它固定成常数,实验数会大量减少。
一个合理的实验模型应该反映或接近过程机制。 一个好的实验设计应该包含全部显著因子,而尽可能少包含不显著因子。 一个好的预报方程一定包含全部显著因子。找出最显著的因子,才能取得重大突破。
举例: 假设一项任务是制备三氧化二氮。化学手册上有很多制备三氧化二氮的方案。例如
可以罗列出许多可能影响收率的因子,例如,水浴温度,反应温度,反应压力,加水量,加水速度,收集温度,收集方式,等等。 在这个系统中找出任何一组,哪怕是全部变量组成输入 X,收率可能有少许波动,绝不会有重大的突破。 因为 (1) 式不完全正确。 只要是坚持实验模型 (1) 式不变,实验重复一万次也不可能得到重大突破。在这种情况下,我们应该寻找 能够引起重大突破的特别显著的因子。
反思对系统的认识,实际上 (1) 不正确,在反应器内不存在 N2O3 , 而是 NO 与 NO2 的混合物。反应器内有水,必然会发生副反应。水越多,副反应越强烈。 猜想副反应为(可以有别的猜想)
消耗大量的 NO2,导致大量 NO 从尾气流走。丢失了一个 NO2 分子就意味着有一个 NO 分子从尾气流失。 (1) 应该修正为
这里的副反应不可能消灭,或者说,逆转这个副反应的成本太高,不值得这样作。 只能寻找简单经济的方法挽回损失。根据无机化学原理,
对过程机制的新认识由式 (3),(4),(5) 三式组成。 在系统中加入 O2,并控制氧气的流量即可控制 ON 和 NO2 的比例,建立 NO 与 NO2 新的平衡。在损失的 N2O3 中,N 的损失是一半。假设原来的收率为 ρ,则收率损失率为 1-ρ,氧化能挽回 (1-ρ)/2,收率可接近 (1+ρ)/2。这是新系统的收率预期,实验一次成功,代价非常低。
系统发生了改变,必须要设计新的实验,重复上述的参数优化过程。于本例,新系统的预报模型只包含一个变量,氧气的输入速度。只用一个实验就可以达到预期效果, N2O3 收率提高到 55% 左右。
这样的例子不胜枚举。
实验模型的设计是知识高度密集的,是事物规律的高度概括。由于高度的专业性,不懂专业知识不可能设计出合理的实验模型。如果实验模型不合理,求助于数学家,不会成功。换句话说,实验模型不合理,再好的试验设计也无济于事。纯粹数学家解决不了具体工程专业上的问题,除非该数学家具备该工程足够的知识。工程专业与数学相结合是必要的,好的实验模型的建立,往往以数学分析为先导。我将在博文中给出一些具体的例子。
参考
- [G.Taguchi and S.Konishi,ORTHOGONAL ARRAYS AND LINEAR GRAPHS,American Supplier institute,inc.1987
- George.E.P.Box, J.Stuart Hunter, William G.Hunter, Statistics for Experimenters (Second Edition), Wiley-Interscience,2004
- 田口玄一,《正交计划法》,丸善株式会社,东京,1976
- R.I.Jennrich 编著,杨自强译,逐步回归,《数字计算机上用的数学方法》卷Ⅲ(4),科学出版社,北京,1981