Data Structures And Algorithms | 2019-07-04
Data Structures And Algorithms
Isomorphism Problem for 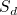 -graphs (1907.01495v1)
-graphs (1907.01495v1)
Deniz Ağaoğlu
2019-07-02
An
-graph is the intersection graph of connected subgraphs of a suitable subdivision of a fixed graph
is an
, each connected component of
is an interval graph and the partial order on the connected components of
. Considering the recognition algorithm given by Chaplick et al., we give an FPT-time algorithm to solve the isomorphism problem for
. Finally, we show that the graph isomorphism problem for
Faster and Better Nested Dissection Orders for Customizable Contraction Hierarchies (1906.11811v2)
Lars Gottesbüren, Michael Hamann, Tim Niklas Uhl, Dorothea Wagner
2019-06-27
Graph partitioning has many applications. We consider the acceleration of shortest path queries in road networks using Customizable Contraction Hierarchies (CCH). It is based on computing a nested dissection order by recursively dividing the road network into parts. Recently, with FlowCutter and Inertial Flow, two flow-based graph bipartitioning algorithms have been proposed for road networks. While FlowCutter achieves high-quality results and thus fast query times, it is rather slow. Inertial Flow is particularly fast due to the use of geographical information while still achieving decent query times. We combine the techniques of both algorithms to achieve more than six times faster preprocessing times than FlowCutter and even faster queries on the Europe road network. We show that using 16 cores of a shared-memory machine, this preprocessing needs four minutes.
Suffix Trees, DAWGs and CDAWGs for Forward and Backward Tries (1904.04513v3)
Shunsuke Inenaga
2019-04-09
The suffix tree, DAWG, and CDAWG are fundamental indexing structures of a string, with a number of applications in bioinformatics, information retrieval, data mining, etc. An edge-labeled rooted tree (trie) is a natural generalization of a string, which can also be seen as a compact representation of a set of strings. Breslauer [TCS 191(1-2): 131-144, 1998] proposed the suffix tree for a backward trie, where the strings in the trie are read in the leaf-to-root direction. In contrast to a backward trie, we call a usual trie as a forward trie. Despite a few follow-up works after Breslauer's paper, indexing forward/backward tries is not well understood yet. In this paper, we show a full perspective on the sizes of indexing structures such as suffix trees, DAWGs, and CDAWGs for forward and backward tries. In particular, we show that the size of the DAWG for a forward trie with
nodes is
, where
is the number of distinct characters in the trie. This becomes
for a large alphabet. Still, we show that there is a compact
-space representation of the DAWG for a forward trie over any alphabet, and present an
Proving tree algorithms for succinct data structures (1904.02809v2)
Reynald Affeldt, Jacques Garrigue, Xuanrui Qi, Kazunari Tanaka
2019-04-04
Succinct data structures give space-efficient representations of large amounts of data without sacrificing performance. They rely one cleverly designed data representations and algorithms. We present here the formalization in Coq/SSReflect of two different tree-based succinct representations and their accompanying algorithms. One is the Level-Order Unary Degree Sequence, which encodes the structure of a tree in breadth-first order as a sequence of bits, where access operations can be defined in terms of Rank and Select, which work in constant time for static bit sequences. The other represents dynamic bit sequences as binary balanced trees, where Rank and Select present a low logarithmic overhead compared to their static versions, and with efficient insertion and deletion. The two can be stacked to provide a dynamic representation of dictionaries for instance. While both representations are well-known, we believe this to be their first formalization and a needed step towards provably-safe implementations of big data.
A hybrid algorithm framework for small quantum computers with application to finding Hamiltonian cycles (1907.01258v1)
Yimin Ge, Vedran Dunjko
2019-07-02
Recent works have shown that quantum computers can polynomially speed up certain SAT-solving algorithms even when the number of available qubits is significantly smaller than the number of variables. Here we generalise this approach. We present a framework for hybrid quantum-classical algorithms which utilise quantum computers significantly smaller than the problem size. Given an arbitrarily small ratio of the quantum computer to the instance size, we achieve polynomial speedups for classical divide-and-conquer algorithms, provided that certain criteria on the time- and space-efficiency are met. We demonstrate how this approach can be used to enhance Eppstein's algorithm for the cubic Hamiltonian cycle problem, and achieve a polynomial speedup for any ratio of the number of qubits to the size of the graph.
Geometric Crossing-Minimization -- A Scalable Randomized Approach (1907.01243v1)
Marcel Radermacher, Ignaz Rutter
2019-07-02
We consider the minimization of edge-crossings in geometric drawings of graphs
, i.e., in drawings where each edge is depicted as a line segment. The respective decision problem is NP-hard [Bienstock, '91]. In contrast to theory and the topological setting, the geometric setting did not receive a lot of attention in practice. Prior work [Radermacher et al., ALENEX'18] is limited to the crossing-minimization in geometric graphs with less than
edges. The described heuristics base on the primitive operation of moving a single vertex
to its crossing-minimal position, i.e., the position in
that minimizes the number of crossings on edges incident to
. This is necessary but not sufficient to cope with graphs with a few thousand edges. In order to handle larger graphs, we drop the condition that each vertex
and each position
for
crossings. In this case, we prove that with a random subset of the edges of size
the co-crossing number of a degree-
vertex
that do not cross, can be approximated by an arbitrary but fixed factor
with high probability. In our experimental evaluation, we show that the randomized approach reduces the number of crossings in graphs with up to
edges considerably. The evaluation suggests that depending on the degree-distribution different strategies result in the fewest number of crossings.
On the VC-dimension of convex sets and half-spaces (1907.01241v1)
Nicolas Grelier, Saeed Gh. Ilchi, Tillmann Miltzow, Shakhar Smorodinsky
2019-07-02
A family
of convex sets in the plane defines a hypergraph
as follows. Every subfamily
defines a hyperedge of
that fully contains
, and no other set of
, and this is tight. In contrast, we show the VC-dimension of convex sets in the plane (not necessarily disjoint) is unbounded. We also show that the VC-dimension is unbounded for pairwise disjoint convex sets in
, for
. We focus on, possibly intersecting, segments in the plane and determine that the VC-dimension is always at most
. And this is tight, as we construct a set of five segments that can be shattered. We give two exemplary applications. One for a geometric set cover problem and one for a range-query data structure problem, to motivate our findings.
Representing fitness landscapes by valued constraints to understand the complexity of local search (1907.01218v1)
Artem Kaznatcheev, David A. Cohen, Peter G. Jeavons
2019-07-02
Local search is widely used to solve combinatorial optimisation problems and to model biological evolution, but the performance of local search algorithms on different kinds of fitness landscapes is poorly understood. Here we introduce a natural approach to modelling fitness landscapes using valued constraints. This allows us to investigate minimal representations (normal forms) and to consider the effects of the structure of the constraint graph on the tractability of local search. First, we show that for fitness landscapes representable by binary Boolean valued constraints there is a minimal necessary constraint graph that can be easily computed. Second, we consider landscapes as equivalent if they allow the same (improving) local search moves; we show that a minimal normal form still exists, but is NP-hard to compute. Next we consider the complexity of local search on fitness landscapes modelled by valued constraints with restricted forms of constraint graph. In the binary Boolean case, we prove that a tree-structured constraint graph gives a tight quadratic bound on the number of improving moves made by any local search; hence, any landscape that can be represented by such a model will be tractable for local search. We build two families of examples to show that both the conditions in our tractability result are essential. With domain size three, even just a path of binary constraints can model a landscape with an exponentially long sequence of improving moves. With a treewidth two constraint graph, even with a maximum degree of three, binary Boolean constraints can model a landscape with an exponentially long sequence of improving moves.
Matched Filters for Noisy Induced Subgraph Detection (1803.02423v3)
Daniel L. Sussman, Youngser Park, Carey E. Priebe, Vince Lyzinski
2018-03-06
The problem of finding the vertex correspondence between two noisy graphs with different number of vertices where the smaller graph is still large has many applications in social networks, neuroscience, and computer vision. We propose a solution to this problem via a graph matching matched filter: centering and padding the smaller adjacency matrix and applying graph matching methods to align it to the larger network. The centering and padding schemes can be incorporated into any algorithm that matches using adjacency matrices. Under a statistical model for correlated pairs of graphs, which yields a noisy copy of the small graph within the larger graph, the resulting optimization problem can be guaranteed to recover the true vertex correspondence between the networks. However, there are currently no efficient algorithms for solving this problem. To illustrate the possibilities and challenges of such problems, we use an algorithm that can exploit a partially known correspondence and show via varied simulations and applications to {\it Drosophila} and human connectomes that this approach can achieve good performance.
On Slicing Sorted Integer Sequences (1907.01032v1)
Giulio Ermanno Pibiri
2019-07-01
Representing sorted integer sequences in small space is a central problem for large-scale retrieval systems such as Web search engines. Efficient query resolution, e.g., intersection or random access, is achieved by carefully partitioning the sequences. In this work we describe and compare two different partitioning paradigms: partitioning by cardinality and partitioning by universe. Although the ideas behind such paradigms have been known in the coding and algorithmic community since many years, inverted index compression has extensively adopted the former paradigm, whereas the latter has received only little attention. As a result, an experimental comparison between these two is missing for the setting of inverted index compression. We also propose and implement a solution that recursively slices the universe of representation of a sequence to achieve compact storage and attain to fast query execution. Albeit larger than some state-of-the-art representations, this slicing approach substantially improves the performance of list intersections and unions while operating in compressed space, thus offering an excellent space/time trade-off for the problem.