Data Structures And Algorithms | 2019-07-08
Data Structures And Algorithms
Locally Private k-Means Clustering (1907.02513v1)
Uri Stemmer
2019-07-04
We design a new algorithm for the Euclidean
-means problem that operates in the local model of differential privacy. Unlike in the non-private literature, differentially private algorithms for the
, our algorithm guarantees
multiplicative error and
additive error for an arbitrarily small constant
, whereas all previous algorithms in the local model on had additive error
. We give a simple lower bound showing that additive error of
is necessary for
UnLimited TRAnsfers for Multi-Modal Route Planning: An Efficient Solution (1906.04832v2)
Moritz Baum, Valentin Buchhold, Jonas Sauer, Dorothea Wagner, Tobias Zündorf
2019-06-11
We study a multi-modal route planning scenario consisting of a public transit network and a transfer graph representing a secondary transportation mode (e.g., walking or taxis). The objective is to compute all journeys that are Pareto-optimal with respect to arrival time and the number of required transfers. While various existing algorithms can efficiently compute optimal journeys in either a pure public transit network or a pure transfer graph, combining the two increases running times significantly. As a result, even walking between stops is typically limited by a maximal duration or distance, or by requiring the transfer graph to be transitively closed. To overcome these shortcomings, we propose a novel preprocessing technique called ULTRA (UnLimited TRAnsfers): Given a complete transfer graph (without any limitations, representing an arbitrary non-schedule-based mode of transportation), we compute a small number of transfer shortcuts that are provably sufficient for computing all Pareto-optimal journeys. We demonstrate the practicality of our approach by showing that these transfer shortcuts can be integrated into a variety of state-of-the-art public transit algorithms, establishing the ULTRA-Query algorithm family. Our extensive experimental evaluation shows that ULTRA is able to improve these algorithms from limited to unlimited transfers without sacrificing query speed, yielding the fastest known algorithms for multi-modal routing. This is true not just for walking, but also for other transfer modes such as cycling or driving.
Fully-Functional Suffix Trees and Optimal Text Searching in BWT-runs Bounded Space (1809.02792v2)
Travis Gagie, Gonzalo Navarro, Nicola Prezza
2018-09-08
Indexing highly repetitive texts - such as genomic databases, software repositories and versioned text collections - has become an important problem since the turn of the millennium. A relevant compressibility measure for repetitive texts is r, the number of runs in their Burrows-Wheeler Transforms (BWTs). One of the earliest indexes for repetitive collections, the Run-Length FM-index, used O(r) space and was able to efficiently count the number of occurrences of a pattern of length m in the text (in loglogarithmic time per pattern symbol, with current techniques). However, it was unable to locate the positions of those occurrences efficiently within a space bounded in terms of r. In this paper we close this long-standing problem, showing how to extend the Run-Length FM-index so that it can locate the occ occurrences efficiently within O(r) space (in loglogarithmic time each), and reaching optimal time, O(m + occ), within O(r log log w ({\sigma} + n/r)) space, for a text of length n over an alphabet of size {\sigma} on a RAM machine with words of w = {\Omega}(log n) bits. Within that space, our index can also count in optimal time, O(m). Multiplying the space by O(w/ log {\sigma}), we support count and locate in O(dm log({\sigma})/we) and O(dm log({\sigma})/we + occ) time, which is optimal in the packed setting and had not been obtained before in compressed space. We also describe a structure using O(r log(n/r)) space that replaces the text and extracts any text substring of length
in almost-optimal time O(log(n/r) +log({\sigma})/w). Within that space, we similarly provide direct access to suffix array, inverse suffix array, and longest common prefix array cells, and extend these capabilities to full suffix tree functionality, typically in O(log(n/r)) time per operation.
Refining the  -index (1802.05906v6)
-index (1802.05906v6)
Hideo Bannai, Travis Gagie, Tomohiro I
2018-02-16
Gagie, Navarro and Prezza's
Expansion Testing using Quantum Fast-Forwarding and Seed Sets (1907.02369v1)
Simon Apers
2019-07-04
Expansion testing aims to decide whether an
, or is far from any such graph. We propose a quantum expansion tester with complexity
. This accelerates the
classical tester by Goldreich and Ron [Algorithmica '02], and combines the
and
quantum speedups by Ambainis, Childs and Liu [RANDOM '11] and Apers and Sarlette [QIC '19], respectively. The latter approach builds on a quantum fast-forwarding scheme, which we improve upon by initially growing a seed set in the graph. To grow this seed set we borrow a so-called evolving set process from the graph clustering literature, which allows to grow an appropriately local seed set.
Fixed-parameter tractability of counting small minimum 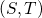 -cuts (1907.02353v1)
-cuts (1907.02353v1)
Pierre Bergé, Benjamin Mouscadet, Arpad Rimmel, Joanna Tomasik
2019-07-04
The parameterized complexity of counting minimum cuts stands as a natural question because Ball and Provan showed its #P-completeness. For any undirected graph
and two disjoint sets of its vertices
, we design a fixed-parameter tractable algorithm which counts minimum edge
. Our algorithm operates on a transformed graph instance. This transformation, called drainage, reveals a collection of at most
successive minimum
. We prove that any minimum
contains edges of at least one cut
. Initially dedicated to counting minimum cuts, it can be modified to obtain an FPT sampling of minimum edge
Concur: An Algorithm for Merging Concurrent Changes without Conflicts (1303.7462v8)
James Smith
2013-03-29
Suppose you and I are both editing a document. You make and change and I make a change, concurrently. Now if we want to still be seeing the same document then I need to apply your change after mine and you mine after yours. But we can't just apply them willy-nilly. I must amend yours somehow and you mine. If my change is written D, yours d, and the amended changes D.d and d.D, we get DD.d=dd.D as long as applying is written * and we don't care about what we're applying the changes to. We start by proving this identity for single changes and finish by proving it for many.
External memory priority queues with decrease-key and applications to graph algorithms (1903.03147v2)
John Iacono, Riko Jacob, Konstantinos Tsakalidis
2019-03-07
We present priority queues in the external memory model with block size
and main memory size
that support on
elements, operation Update (a combination of operations Insert and Decrease-Key) in
amortized I/Os and operations Extract-Min and Delete in
amortized I/Os, for any real
, using
blocks. Previous I/O-efficient priority queues either support these operations in
amortized I/Os [Kumar and Schwabe, SPDP '96] or support only operations Insert, Delete and Extract-Min in optimal
I/Os and operation Extract on
extracted elements in
amortized I/Os, using
blocks. Previous results achieve
I/Os, respectively [Buchsbaum et al., SODA '00]. Our results imply improved
I/Os for single-source shortest paths, depth-first search and breadth-first search algorithms on massive directed dense graphs
with
and
, which is equal to the I/O-optimal bound for sorting
values in external memory.
Optimal transport on large networks a practitioner guide (1907.02320v1)
Arthur Charpentier, Alfred Galichon, Lucas Vernet
2019-07-04
This article presents a set of tools for the modeling of a spatial allocation problem in a large geographic market and gives examples of applications. In our settings, the market is described by a network that maps the cost of travel between each pair of adjacent locations. Two types of agents are located at the nodes of this network. The buyers choose the most competitive sellers depending on their prices and the cost to reach them. Their utility is assumed additive in both these quantities. Each seller, taking as given other sellers prices, sets her own price to have a demand equal to the one we observed. We give a linear programming formulation for the equilibrium conditions. After formally introducing our model we apply it on two examples: prices offered by petrol stations and quality of services provided by maternity wards. These examples illustrate the applicability of our model to aggregate demand, rank prices and estimate cost structure over the network. We insist on the possibility of applications to large scale data sets using modern linear programming solvers such as Gurobi. In addition to this paper we released a R toolbox to implement our results and an online tutorial (http://optimalnetwork.github.io)
The Alternating BWT: an algorithmic perspective (1907.02308v1)
Raffaele Giancarlo, Giovanni Manzini, Antonio Restivo, Giovanna Rosone, Marinella Sciortino
2019-07-04
The Burrows-Wheeler Transform (BWT) is a word transformation introduced in 1994 for Data Compression. It has become a fundamental tool for designing self-indexing data structures, with important applications in several area in science and engineering. The Alternating Burrows-Wheeler Transform (ABWT) is another transformation recently introduced in [Gessel et al. 2012] and studied in the field of Combinatorics on Words. It is analogous to the BWT, except that it uses an alternating lexicographical order instead of the usual one. Building on results in [Giancarlo et al. 2018], where we have shown that BWT and ABWT are part of a larger class of reversible transformations, here we provide a combinatorial and algorithmic study of the novel transform ABWT. We establish a deep analogy between BWT and ABWT by proving they are the only ones in the above mentioned class to be rank-invertible, a novel notion guaranteeing efficient invertibility. In addition, we show that the backward-search procedure can be efficiently generalized to the ABWT; this result implies that also the ABWT can be used as a basis for efficient compressed full text indices. Finally, we prove that the ABWT can be efficiently computed by using a combination of the Difference Cover suffix sorting algorithm [K"{a}rkk"{a}inen et al., 2006] with a linear time algorithm for finding the minimal cyclic rotation of a word with respect to the alternating lexicographical order.
Congratulations @binarytree! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!