Data Structures And Algorithms | 2019-07-12
Data Structures And Algorithms
Vertex-Fault Tolerant Complete Matching in Bipartite graphs: the Biregular Case (1907.04844v1)
Sylwia Cichacz, Karol Suchan
2019-07-10
Given a family
of graphs and a positive integer
, a graph
is called vertex
, if
contains some
as a subgraph, for every
with
. Vertex-fault-tolerance has been introduced by Hayes [A graph model for fault-tolerant computing systems, IEEE Transactions on Computers, C-25 (1976), pp. 875-884.], and has been studied in view of potential applications in the design of interconnection networks operating correctly in the presence of faults. We define the Fault-Tolerant Complete Matching (FTCM) Problem in bipartite graphs of order
: to design a bipartite
, with
,
,
, that has a FTCM, and the tuple
, where
and
are the maximum degree in
and
, respectively, is lexicographically minimum.
vertices from
that has a complete matching, i.e., a matching of size
. We show that if
is integer, solutions of the FTCM Problem can be found among
-regular bipartite graphs of order
, and
. If
then all
, it is not the case. We characterize the values of
,
, and
that admit an
Approximately counting and sampling small witnesses using a colourful decision oracle (1907.04826v1)
Holger Dell, John Lapinskas, Kitty Meeks
2019-07-10
In this paper, we prove "black box" results for turning algorithms which decide whether or not a witness exists into algorithms to approximately count the number of witnesses, or to sample from the set of witnesses approximately uniformly, with essentially the same running time. We do so by extending the framework of Dell and Lapinskas (STOC 2018), which covers decision problems that can be expressed as edge detection in bipartite graphs given limited oracle access; our framework covers problems which can be expressed as edge detection in arbitrary
Scheduling With Inexact Job Sizes: The Merits of Shortest Processing Time First (1907.04824v1)
Matteo Dell'Amico
2019-07-10
It is well known that size-based scheduling policies, which take into account job size (i.e., the time it takes to run them), can perform very desirably in terms of both response time and fairness. Unfortunately, the requirement of knowing a priori the exact job size is a major obstacle which is frequently insurmountable in practice. Often, it is possible to get a coarse estimation of job size, but unfortunately analytical results with inexact job sizes are challenging to obtain, and simulation-based studies show that several size-based algorithm are severely impacted by job estimation errors. For example, Shortest Remaining Processing Time (SRPT), which yields optimal mean sojourn time when job sizes are known exactly, can drastically underperform when it is fed inexact job sizes. Some algorithms have been proposed to better handle size estimation errors, but they are somewhat complex and this makes their analysis challenging. We consider Shortest Processing Time (SPT), a simplification of SRPT that skips the update of "remaining" job size and results in a preemptive algorithm that simply schedules the job with the shortest estimated processing time. When job size is inexact, SPT performs comparably to the best known algorithms in the presence of errors, while being definitely simpler. In this work, SPT is evaluated through simulation, showing near-optimal performance in many cases, with the hope that its simplicity can open the way to analytical evaluation even when inexact inputs are considered.
Improved Convergence for 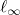 and
and 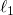 Regression via Iteratively Reweighted Least Squares (1902.06391v2)
Regression via Iteratively Reweighted Least Squares (1902.06391v2)
Alina Ene, Adrian Vladu
2019-02-18
The iteratively reweighted least squares method (IRLS) is a popular technique used in practice for solving regression problems. Various versions of this method have been proposed, but their theoretical analyses failed to capture the good practical performance. In this paper we propose a simple and natural version of IRLS for solving
-approximate solution in
iterations, where
, which is atypical for the optimization of non-smooth functions. This improves upon the more complex algorithms of Chin et al. (ITCS '12), and Christiano et al. (STOC '11) by a factor of at least
, and yields a truly efficient natural algorithm for the slime mold dynamics (Straszak-Vishnoi, SODA '16, ITCS '16, ITCS '17).
Travelling on Graphs with Small Highway Dimension (1902.07040v2)
Yann Disser, Andreas Emil Feldmann, Max Klimm, Jochen Konemann
2019-02-19
We study the Travelling Salesperson (TSP) and the Steiner Tree problem (STP) in graphs of low highway dimension. This graph parameter was introduced by Abraham et al. [SODA 2010] as a model for transportation networks, on which TSP and STP naturally occur for various applications in logistics. It was previously shown [Feldmann et al. ICALP 2015] that these problems admit a quasi-polynomial time approximation scheme (QPTAS) on graphs of constant highway dimension. We demonstrate that a significant improvement is possible in the special case when the highway dimension is 1, for which we present a fully-polynomial time approximation scheme (FPTAS). We also prove that STP is weakly NP-hard for these restricted graphs. For TSP we show NP-hardness for graphs of highway dimension 6, which answers an open problem posed in [Feldmann et al. ICALP 2015].
Sparse Regular Expression Matching (1907.04752v1)
Philip Bille, Inge Li Gørtz
2019-07-10
We present the first algorithm for regular expression matching that can take advantage of sparsity in the input instance. Our main result is a new algorithm that solves regular expression matching in
time, where
is the \emph{density} of the instance, defined as the total number of active states in a simulation of the position automaton. This measure is a lower bound on the total number of active states in simulations of all classic polynomial sized finite automata. Our bound improves the best known bounds for regular expression matching by almost a linear factor in the density of the problem. The key component in the result is a novel linear space representation of the position automaton that supports state-set transition computation in near-linear time in the size of the input and output state sets.
Efficient Gauss Elimination for Near-Quadratic Matrices with One Short Random Block per Row, with Applications (1907.04750v1)
Martin Dietzfelbinger Stefan Walzer
2019-07-10
In this paper we identify a new class of sparse near-quadratic random Boolean matrices that have full row rank over
with high probability and can be transformed into echelon form in almost linear time by a simple version of Gauss elimination. The random matrix with dimensions
is generated as follows: In each row, identify a block of length
at a random position. The entries outside the block are 0, the entries inside the block are given by fair coin tosses. Sorting the rows according to the positions of the blocks transforms the matrix into a kind of band matrix, on which, as it turns out, Gauss elimination works very efficiently with high probability. For the proof, the effects of Gauss elimination are interpreted as a ("coin-flipping") variant of Robin Hood hashing, whose behaviour can be captured in terms of a simple Markov model from queuing theory. Bounds for expected construction time and high success probability follow from results in this area. By employing hashing, this matrix family leads to a new implementation of a retrieval data structure, which represents an arbitrary function
for some set
of
keys. It requires
bits of space, construction takes
) expected time on a word RAM, while queries take
time and access only one contiguous segment of
bits in the representation. The method is competitive with state-of-the-art methods. By well-established methods the retrieval data structure leads to efficient constructions of (static) perfect hash functions and (static) Bloom filters with almost optimal space and very local storage access patterns for queries.
Dense Peelable Random Uniform Hypergraphs (1907.04749v1)
Martin Dietzfelbinger, Stefan Walzer
2019-07-10
We describe a new family of
, even when the edge density (number of edges over vertices) is close to
. In our construction, the vertex set is partitioned into linearly arranged segments and each edge is incident to random vertices of
for peelability of our hypergraphs (
,
,
, ...) are well beyond the corresponding thresholds (
,
,
, ...) of standard
-uniform hypergraphs as a drop-in replacement for the standard
bits to
bits (
Constant-Time Dynamic 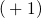 -Coloring and Weight Approximation for Minimum Spanning Forest: Dynamic Algorithms Meet Property Testing (1907.04745v1)
-Coloring and Weight Approximation for Minimum Spanning Forest: Dynamic Algorithms Meet Property Testing (1907.04745v1)
Monika Henzinger, Pan Peng
2019-07-10
With few exceptions (namely, algorithms for maximal matching,
update/query time. Showing for the first time that techniques from property testing can lead to constant-time fully dynamic graph algorithms we prove the following results: (1) We give a fully dynamic (Las-Vegas style) algorithm with constant expected amortized time per update that maintains a proper
-vertex coloring of a graph with maximum degree at most
-time algorithm by Bhattacharya et al. (SODA 2018). We show that our result does not only have optimal running time, but is also optimal in the sense that already deciding whether a
-approximation of the weight
of the minimum spanning forest of a graph
. Our deterministic algorithm takes
worst-case time, which is constant if both
and
are constant. This is somewhat surprising as a lower bound by Patrascu and Demaine (SIAM J. Comput. 2006) shows that it takes
. Our randomized (Monte-Carlo style) algorithm works with high probability and runs in worst-case
time if
, where
is the minimum number of edges in the graph throughout all the updates. It works even against an adaptive adversary.
Matroid Bases with Cardinality Constraints on the Intersection (1907.04741v1)
Stefan Lendl, Britta Peis, Veerle Timmermans
2019-07-10
Given two matroids
and
on a common ground set
with base sets
and
, some integer
, and two cost functions
, we consider the optimization problem to find a basis
and a basis
minimizing cost
subject to either a lower bound constraint
, an upper bound constraint
, or an equality constraint
on the size of the intersection of the two bases
and
. The problem with lower bound constraint turns out to be a generalization of the Recoverable Robust Matroid problem under interval uncertainty representation for which the question for a strongly polynomial-time algorithm was left as an open question by Hradovich et al. We show that the two problems with lower and upper bound constraints on the size of the intersection can be reduced to weighted matroid intersection, and thus be solved with a strongly polynomial-time primal-dual algorithm. The question whether the problem with equality constraint can also be solved efficiently turned out to be a lot harder. As our main result, we present a strongly-polynomial, primal-dual algorithm for the problem with equality constraint on the size of the intersection. Additionally, we discuss generalizations of the problems from matroids to polymatroids, and from two to three or more matroids.