4-3-2 머신 러닝 SVM(Support Vector Machine) 기법이란?
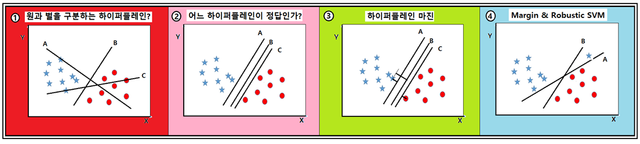
XY 평면 위의 2종류 데이터 클라스 즉 각각 원과 별로 구분되는 라벨 명을 가지는 데이터 군들에 대해서 데이터들을 구분해 줄 수 있는 하이퍼플레인을 고려해 보자.
위와 같은 2차원 데이터 군들에 대해서는 하이퍼플레인이 하나의 직선이나 곡선으로 표현되지만 3차원 공간 상의 데이터라면 3차원적인 평면이나 곡면이 될 수도 있다.
⓵번 그림에서 두 종류의 데이터를 제대로 구분할 수 있는 선형의 하이퍼플레인은 어는 것인가? 정답 B 이다.
⓶번 그림에서 하이퍼플레인 후보 A, B, C 중에서 어떤 기준으로 어느 것을 하이퍼 플레인으로 선택할 것인가?
⓷번 그림에서 볼 수 있듯이 마진(Margin) 개년을 도입하자 마진이란 하이퍼플레인에서 근접한 데이터까지의 수직 거리가 기준이 된다. B를 택하면 근접한 별과 원으로부터의 마진이 최대가 된다.
⓸번 그림에서 B는 A보다 마진이 크다. 하지만 SVM 에서는 마진 최대값을 택하기 이전에 두 종류의 데이터가 식별이 가능하도록 구분이 선행되어야 하므로 A 가 하이퍼플레인이 된다.
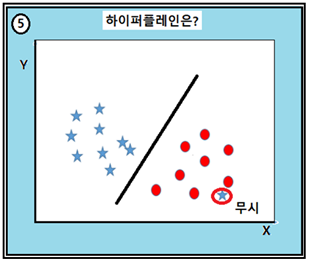
이 그림에서 별 데이터 하나가 원 데이터군의 가장자리에 외떨어진 체 위치하고 있을 때 SVM 은 robustic 한 특성으로 인해 그 데이터를 무시하도록 처리된다.
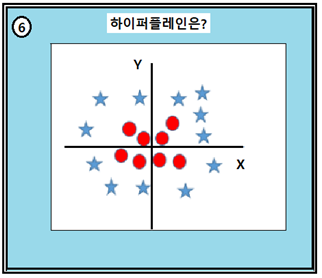
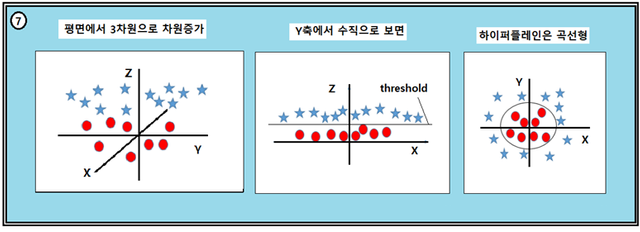
원 데이터 군이 가운데 영역에 뭉쳐 있을 때 하이퍼 플레인은 선형으로 표현하기 곤란하며 곡선형이 될 수밖에 없다. 이들 원 데이터 군을 별 데이터군으로부터 어떤 방법으로 구분해 낼 수 있을까? XY 평면 상의 데이터를 원이든 별이든 r = (x, y) 인 벡터로 표현하자. SVM은 벡터의 내적 계산을 통해 데이터 변환 작업을 실시한다.
Z = S(x,y) = r∙r = (x, y) ∙(x, y) = x^2+y^2
만약 원 데이터군들의 좌표 (x, y)에서 x 와 y 의 절대 값들이 1 보다 작으며 아울러 별 데이터들의 값들은 1보다 크다면 한파원 높아진 3차원 공간에서 관찰할 수 있는 Z = S(x, y)는 다음 그림과 같이 threshold에 의해 구분될 수 있음을 알 수 있을 것이다.
이 SVM 기법을 데모하기 위한 적절한 TensorFlow 예제는 없는 듯하다. 머신 러닝 파이선 코드를 작성 실행하기 위해 아나콘다를 설치할 때 예제가 scikit-learn 라이브러리 모듈을 사용하는 Iris Flower 데이터 통계 분석이었다는 점을 기억할 필요가 있다. 즉 이 SVM 기법은 통계학 분야에서 발전된 방법이라 예제도 결국 scikit-learn 라이브러리 모듈을 사용분야에서 찾아보도록 하자.
짱짱맨 호출에 응답하여 보팅하였습니다. 즐거운 주말 보내세요.
굴 잘 보고 갑니다 디클릭으로 글좀 올려줘요 그래야 꾸욱해주죠 ^^
Posted using Partiko iOS