4-3 인터넷 영화 데이터베이스(IMDB) CSV 데이터 변환

머신 러닝이 많이 컷는지 벌써 수능 시험에 도전하고 있다. 수능평가처럼 지문을 제시한 후에 문맥을 이해하고 있는지 질문하는 것이다.
질문 예를 들자. 헤리포터는 1997년부터 2007년까지 연제된 영국의 작가 조안 롤링의 판타지 소설 시리즈로서 이모네 집 계단 밑 벽장에서 생활하던 열한 살 소년 해리 포터가 호그와트 마법학교에 가게 되면서 겪게 되는 판타지 이야기를 그리고 있다. ∙∙∙
질문: 해리는 호그와트에 들어가기 전에 어디서 살았나요?
머신 러닝이 풀어야 할 문제 사례이다. 결국 우리가 풀어야 할 문제와 아무런 차이가 없다. 학생들이야 시각적으로 문제를 읽어 보겠지만 머신 러닝을 파일을 읽어 들이면 된다. 파일의 성격에 따라서 그것이 웹이라면 문장의 의미 파악을 위해서 불필요하다고 생각되는 요소들인 HTML부호와 같은 것들을 필터링 하여 털어낼 필요가 있다.
머신 러닝은 이런 시험문제를 10분에 무려 3800개 이상의 문제를 풀며 91.2점을 넘어야 일반 성인 수준의 언어능력을 가진 AI로서 합격 판정이 난다고 한다. 이 기준 점수는 4년제 대학 졸업자를 대상으로 30초에 한 문제씩 33시간에 걸쳐 테스트하여 평균한 점수이다. LG CNS 가 AI용 문제를 출제하고 네이버 카카오 알앤비소프트 인라이플 광주과학기술원등 15개 업체가 시험을 보았는데 1등은 익명의 AI(94.08점)이고 네이버가 2등(92.42점) 카카오가 3등(92.1점) 광주과학기술원 6등(91.24점)을 했다는군요.
반면에 영문 Wikipedia를 이용해 10만 7785개의 질문을 만든 미국 스탠퍼드대 AI 시험 SQuAD 시험 결과 순위는 구글(89.147점), 마이크로소프트(87.165점), 알리바바(80.209점),IBM(75.507점)으로서 커트라인이 82.99점이었다. 구글과 마이크로소프트만 간신히 통과했고 나머지는 개털이 되어 버렸다. 아마존 시험공부를 안했는지 창피 당할까봐 시험을 포기했다고 한다.
LG CNS 가 출제하는 시험에 응시하려면 수만개의 한국어 문장을 학습해야 하며 단어수로는 170만개에 이른다. 문맥까지 파악할 수 있어야 한다.
인터넷 영화 리뷰 데이터베이스 건도 AI 수능 시험 문제 학습과 유사성이 많으므로 앞으로 자신의 AI 개발에 활용도가 클 것이다.
Imdb 가 준비되었으면 읽어 들인 후 PANDS 라이브러리의 지원 하에 csv 파일 전환함과 아울러 PyPind 라이브러리 지원을 받아 progrss를 모니터랄 해 보자.
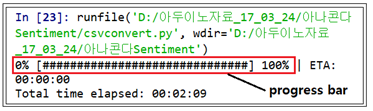
csvconvert.py를 실행하면 progress bar 가 나타나며 5분가량의 시간이 소요될 수 있다.
다음은 progress bar 사례이다.
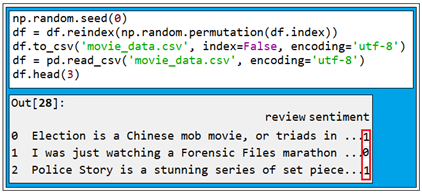
이 작업을 완료한 후 df 명령을 사용하여 3줄의 결과를 출력해보자. 다음 그림에서 보여주는 5줄의 코드가 비록 csvconvert.py 에 포함되어 있지만 이 부분은 별도로 셸(Shell)에서 인터프리터 방식으로 실행을 해야 출력 결과를 볼 수 있다. pos 폴더에서 읽은 내용은 라벨 명을 1로 neg 폴더에서 읽은 내용은 0으로 라벨 명을 부여한다.
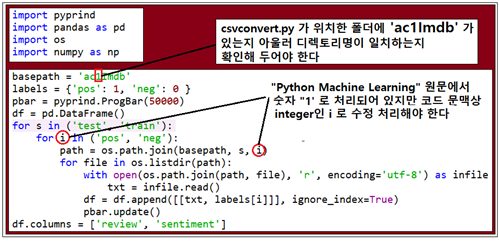
#csvconvert.py
import pyprind
import pandas as pd
import os
import numpy as np
basepath = 'ac1Imdb'
labels = {'pos': 1, 'neg': 0 }
pbar = pyprind.ProgBar(50000)
df = pd.DataFrame()
for s in ('test', 'train'):
for i in ('pos', 'neg'):
path = os.path.join(basepath, s, i)
for file in os.listdir(path):
with open(os.path.join(path, file), 'r', encoding='utf-8') as infile:
txt = infile.read()
df = df.append([[txt, labels[i]]], ignore_index=True)
pbar.update()
df.columns = ['review', 'sentiment']
np.random.seed(0)
df = df.reindex(np.random.permutation(df.index))
df.to_csv('movie_data.csv', index=False, encoding='utf-8')
df = pd.read_csv('movie_data.csv', encoding='utf-8')
df.head(3)
"""
0% [##############################] 100% | ETA: 00:00:00
Total time elapsed: 00:02:08
df.head(3)
Out[28]:
review sentiment
0 Election is a Chinese mob movie, or triads in ... 1
1 I was just watching a Forensic Files marathon ... 0
2 Police Story is a stunning series of set piece... 1
"""

짱짱맨 호출에 응답하였습니다.
Congratulations @codingart! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!