핸즈온 머신러닝을 공부하면서 정리하고 있습니다. 14장 순환 신경망 #11
아래와 같은 순서로 책을 보시면 됩니다. 파이썬 언어를 공부해야 합니다. => 판다스를 사용할 수 있어야 합니다. => 머신러닝, 딥러닝을 공부할 수 있습니다. 제가 정리한 글에 있습니다. 이런 순서로 공부하고 선형대수나 미분에 대한 내용을 개발자를 위한 수학책으로 따로 정리하면 될 것 같습니다. 좌절과 희열을 반복하면서 보고 있는데 점점 좌절보다는 희망을 보고 있습니다. 기계학습과 강화 학습을 공부하시는 모든 분들 화이팅입니다. ~~~~
https://steemit.com/kr/@papasmf1/73cj22
핸즈온 머신러닝 책의 소스는 아래의 깃허브에 있습니다. 참고하실 수 있습니다.
https://github.com/rickiepark/handson-ml
제가 테스트하고 실습하는 환경은 맥에 아나콘다 최근 패키지를 설치해서 주피터랩으로 실행하고 있습니다. 아나콘다 패키지를 사용하는 경우에 텐서플로는 쉽게 설치할 수 있습니다. ^^
14장 순환 신경망
야구방망이로 공을 칩니다. 수비수는 즉시 공의 궤적을 예측하면서 달리기 시작합니다. 공에서 눈을 떼지 않고 몸을 움직여 마침내 공을 잡습니다. 친구의 말을 대신 마무리하든 아침에 커피 향을 예상하든 미래를 예측하는 것은 우리가 늘 하는 일입니다.
이 장에서는 미래를 예측할 수 있는 네트워크인 순환 신경망 recurrent neural networks(RNN)에 대해 알아보겠습니다. 이 신경망은 주식가격 같은 시계열 데이터를 분석해서 언제 사고팔지 알려줄 수 있습니다. 자율주행 시스템에서는 차의 이동경로를 예측하고 사고를 피하도록 도울 수 있습니다. 일반적으로 이 신경망은 지금까지 봤던 모든 네트워크처럼 고정 길이가 아니라 임의 길이를 가진 시퀀스를 다룰 수 있습니다. 예를 들어 문장, 문서 또는 오디오 샘플을 입력으로 받을 수 있고, 자동 번역, 스피치 투 텍스트 또는 감성 분석같은 자연어 처리에 매우 유용합니다.
14.1 순환 뉴런
지금까지는 활성화 신호가 입력층에서 출력층 한 방향으로만 흐르는 피드포워드 신경망을 살펴봤습니다. 순환 신경망은 피드포워드 신경망과 매우 비슷하지만 뒤쪽으로 향하는 연결도 있다는 점이 다릅니다. 입력을 받아 출력을 만들고 자신에게도 출력을 보내는 뉴련 하나로 구성된 가장 간단한 RNN을 살펴보겠습니다. 이를 시간에 따라 네트워크를 펼쳤다고 말합니다.
14.1.1 메모리 셀
타임 스텝 t에서 순환 뉴런의 출력은 이전 타임 스텝의 모든 입력에 대한 함수이기 때문에 이를 일종의 메모리 형태라고 말할 수 있습니다. 타임 스텝에 걸쳐서 어떤 상태를 보존하는 신경망의 구성 요소를 메모리 셀이라고 합니다. 하나의 순환 뉴런 또는 순환 뉴런의 층은 매우 기본적인 셀입니다. 하지만 이 장 뒷부분에서 더 복잡하고 강력한 종류의 셀을 볼 것입니다.
14.1.2 입력과 출력 시퀀스
RNN은 입력 시퀀스를 받아 출력 시퀀스 만들 수 있습니다. 이는 시퀀스-투-시퀀스 네트워크로, 예를 들어 주식 가격 같은 시계열 데이터를 예측하는데 유용합니다. 최근 N일치의 주식 가격을 주입하면 네트워크는 하루 앞선 가격을 출력해야 합니다.
또는 입력 시퀀스를 네트워크에 주입하고, 마지막을 제외한 모든 출력을 무시할 수 있습니다. 이는 시퀀스-투-벡터 네트워크로, 예를 들어 영화 리뷰에 있는 연속된 단어를 주입하면 네트워크는 감성 점수를 출력합니다.
또한 인코더라 불리는 시퀀스-투-벡터 네트워크 뒤에 디코더라 불리는 벡터-투-시퀀스 네트워크를 연결할 수 있습니다. 이는 지연된 시퀀스-투-시퀀스네트워크로, 예를 들어 한 언어의 문장을 다른 언어로 번역하는데 사용할 수 있습니다.
14.2 텐서플로로 기본 RNN구성하기
내부 구조를 잘 이해하기 위해 먼저 텐서플로의 RNN연산을 전혀 사용하지 않고 매우 간단한 RNN모델을 구현해 보겠습니다. tanh활성화 함수를 사용하는 다섯 개의 순환 뉴런의 층으로 구성된 RNN을 만들겠습니다. 이 RNN은 타임 스텝마다 크기 3의 입력 벡터를 받고 단지 두 개의 타임 스텝에 대해서만 작동한다고 가정하겠습니다. 다음 코드는 두 개의 타임 스텝에 걸쳐 펼쳐진 이 RNN을 구성합니다.
일관된 출력을 위해 유사난수 초기화
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
맷플롯립 설정
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
한글출력
plt.rcParams['font.family'] = 'AppleGothic'
plt.rcParams['axes.unicode_minus'] = False
그림을 저장할 폴더
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "rnn"
def save_fig(fig_id, tight_layout=True):
path = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id + ".png")
if tight_layout:
plt.tight_layout()
plt.savefig(path, format='png', dpi=300)
import tensorflow as tf
#수동으로 RNN만들기
reset_graph()
n_inputs = 3
n_neurons = 5
X0 = tf.placeholder(tf.float32, [None, n_inputs])
X1 = tf.placeholder(tf.float32, [None, n_inputs])
Wx = tf.Variable(tf.random_normal(shape=[n_inputs, n_neurons],dtype=tf.float32))
Wy = tf.Variable(tf.random_normal(shape=[n_neurons,n_neurons],dtype=tf.float32))
b = tf.Variable(tf.zeros([1, n_neurons], dtype=tf.float32))
Y0 = tf.tanh(tf.matmul(X0, Wx) + b)
Y1 = tf.tanh(tf.matmul(Y0, Wy) + tf.matmul(X1, Wx) + b)
init = tf.global_variables_initializer()
이 네트워크는 같은 가중치와 편향을 양쪽 층이 공유한다는 점과 층마다 입력을 주입하고 ㅊ울력을 얻는다는 점을 빼면 두 개의 층이 있는 피드포워드 신경망과 매우 비슷합니다. 이 모델을 실행하려면 두 타임 스텝에 입력을 다음과 같이 주입해야 합니다.
import numpy as np
X0_batch = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 0, 1]]) # t = 0
X1_batch = np.array([[9, 8, 7], [0, 0, 0], [6, 5, 4], [3, 2, 1]]) # t = 1
with tf.Session() as sess:
init.run()
Y0_val, Y1_val = sess.run([Y0, Y1], feed_dict={X0: X0_batch, X1: X1_batch})
이 미니 배치는 네 개의 샘플을 담고 있으며 각 샘플은 두 개의 입력으로 구성된 입력 시퀀스입니다. 결고 Y0_val과 Y1_val은 두 타임 스텝에서 모든 뉴런과 미니배치에 있는 모든 샘플에 대한 네트워크의 출력을 담고 있습니다.
print(Y0_val)
[[-0.0664006 0.9625767 0.68105793 0.7091854 -0.898216 ]
[ 0.9977755 -0.71978897 -0.9965761 0.9673924 -0.9998972 ]
[ 0.99999774 -0.99898803 -0.9999989 0.9967762 -0.9999999 ]
[ 1. -1. -1. -0.99818915 0.9995087 ]]
print(Y1_val)
[[ 1. -1. -1. 0.40200275 -0.9999998 ]
[-0.12210423 0.6280527 0.9671843 -0.9937122 -0.25839362]
[ 0.9999983 -0.9999994 -0.9999975 -0.8594331 -0.9999881 ]
[ 0.99928284 -0.99999803 -0.9999058 0.9857963 -0.92205757]]
그렇게 어렵지 않네요. 하지만 100개의 타임 스텝에서 RNN을 실행해야 한다면 매우 큰 그래프가 만들어질 것입니다. 그럼 텐서플로의 RNN연산을 사용해 동일한 모델을 어떻게 만드는지 살폅겠습니다.
14.2.1 정적으로 타임 스넵 펼치기
static_run()함수는 셀을 연결하여 펼쳐진 RNN네트워크를 만듭니다.
reset_graph()
X0 = tf.placeholder(tf.float32, [None, n_inputs])
X1 = tf.placeholder(tf.float32, [None, n_inputs])
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, [X0, X1],
dtype=tf.float32)
Y0, Y1 = output_seqs
만약 50개의 타임 스텝이 있다면 50개의 엽력 플레이스홀더와 50개의 출럭 텐서를 정의하는건 번거로운 일입니다. 게다가 실행할 때 50개의 플레이스홀더에 데이터를 주입하고 50개의 출력을 받아야 합니다. 이를 좀 간단하게 만들어보죠.
init = tf.global_variables_initializer()
X0_batch = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 0, 1]])
X1_batch = np.array([[9, 8, 7], [0, 0, 0], [6, 5, 4], [3, 2, 1]])
with tf.Session() as sess:
init.run()
Y0_val, Y1_val = sess.run([Y0, Y1], feed_dict={X0: X0_batch, X1: X1_batch})
Y0_val
array([[ 0.30741334, -0.32884315, -0.6542847 , -0.9385059 , 0.52089024],
[ 0.99122757, -0.9542541 , -0.7518079 , -0.9995208 , 0.9820235 ],
[ 0.9999268 , -0.99783254, -0.8247353 , -0.9999963 , 0.99947774],
[ 0.996771 , -0.68750614, 0.8419969 , 0.9303911 , 0.8120684 ]],
dtype=float32)
Y1_val
array([[ 0.99998885, -0.99976057, -0.06679279, -0.9999803 , 0.99982214],
[-0.65249425, -0.51520866, -0.37968954, -0.5922594 , -0.08968391],
[ 0.998624 , -0.99715203, -0.03308626, -0.9991566 , 0.9932902 ],
[ 0.99681675, -0.9598194 , 0.39660627, -0.8307606 , 0.79671973]],
dtype=float32)
from tensorflow_graph_in_jupyter import show_graph
show_graph(tf.get_default_graph())
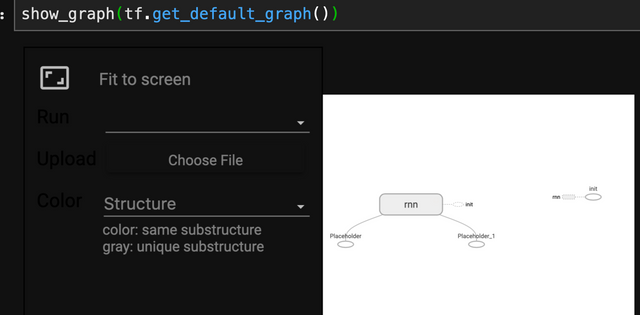
14.2.2 동적으로 타입 스텝 펼치기
dynymic_rnn()함수는 타임 스텝에 걸쳐 셀을 실행하기 위해 while_loop()연산을 사용합니다. 그리고 GPU메모리에서 CPU메모리로 바꾸어 역전파 시에 OOM에러를 피하고 싶다면 swap_memory=True옵션을 설정합니다. 이 함수는 편리하게도 각 타임 스텝의 모든 입력에 대해 텐서 하나를 받고, 타임 스텝마다의 모든 출력을 하나의 텐서로 반환합니다.
14.2.3 가변 길이 입력 시퀀스 다루기
지금까지 고정 길이를 가진 입력 시퀀스만 다루었습니다. 그런데 입력 시퀀스가(예를 들어 문장처럼) 가변 길이면 어떻게 될까요? 이런 경우에는 dynamic_rnn() 또는 static_rnn()함수를 호출할 때 sequence_length매개변수를 설정해야 합니다.
14.3 RNN 훈련하기
RNN을 훈련시키기 위한 기법은 타임 스텝으로 네트워크를 펼치고 보통의 역전파를 사용하는 것입니다. 이런 전력을 BPTT backpropagation through time라고 합니다.
14.3.2 시퀀스 분류기 훈련하기
이번에는 주식가격, 기온, 뇌파 패턴 등과 같은 시계열을 다루는 방법을 살펴보겠습니다. 여기서는 인공적으로 생성한 시계열 데이터의 다음 값을 예측하는 RNN을 훈련시키겠습니다. 각 훈련 샘플은 시계열 데이터에서 연속된 20개의 값을 랜덤하게 선택한 값입니다. 타깃 시퀀스는 타임 스텝 하나만큼 앞으로 이동한 것을 제외하고는 입력 시퀀스와 동일합니다.
#시퀀스 분류기 훈련하기
reset_graph()
n_steps = 28
n_inputs = 28
n_neurons = 150
n_outputs = 10
learning_rate = 0.001
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.int32, [None])
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
outputs, states = tf.nn.dynamic_rnn(basic_cell, X, dtype=tf.float32)
logits = tf.layers.dense(states, n_outputs)
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,
logits=logits)
loss = tf.reduce_mean(xentropy)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
#주의: tf.examples.tutorials.mnist은 삭제될 예정이므로 대신 tf.keras.datasets.mnist를 사용하겠습니다.
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 2828) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 2828) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
X_test = X_test.reshape((-1, n_steps, n_inputs))
X_valid = X_valid.reshape((-1, n_steps, n_inputs))
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
n_epochs = 100
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
X_batch = X_batch.reshape((-1, n_steps, n_inputs))
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_valid = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "배치 데이터 정확도:", acc_batch, "검증 세트 정확도:", acc_valid)
0 배치 데이터 정확도: 0.9533333 검증 세트 정확도: 0.9322
1 배치 데이터 정확도: 0.96 검증 세트 정확도: 0.953
2 배치 데이터 정확도: 0.96 검증 세트 정확도: 0.952
3 배치 데이터 정확도: 0.9533333 검증 세트 정확도: 0.9626
4 배치 데이터 정확도: 0.97333336 검증 세트 정확도: 0.9694
5 배치 데이터 정확도: 0.94 검증 세트 정확도: 0.964
#다층 RNN
reset_graph()
n_steps = 28
n_inputs = 28
n_outputs = 10
learning_rate = 0.001
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.int32, [None])
n_neurons = 100
n_layers = 3
layers = [tf.contrib.rnn.BasicRNNCell(num_units=n_neurons,
activation=tf.nn.relu)
for layer in range(n_layers)]
multi_layer_cell = tf.contrib.rnn.MultiRNNCell(layers)
outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
states_concat = tf.concat(axis=1, values=states)
logits = tf.layers.dense(states_concat, n_outputs)
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
n_epochs = 10
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
X_batch = X_batch.reshape((-1, n_steps, n_inputs))
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_valid = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "배치 데이터 정확도:", acc_batch, "검증 세트 정확도:", acc_valid)
#시계열
t_min, t_max = 0, 30
resolution = 0.1
def time_series(t):
return t * np.sin(t) / 3 + 2 * np.sin(t*5)
def next_batch(batch_size, n_steps):
t0 = np.random.rand(batch_size, 1) * (t_max - t_min - n_steps * resolution)
Ts = t0 + np.arange(0., n_steps + 1) * resolution
ys = time_series(Ts)
return ys[:, :-1].reshape(-1, n_steps, 1), ys[:, 1:].reshape(-1, n_steps, 1)
t = np.linspace(t_min, t_max, int((t_max - t_min) / resolution))
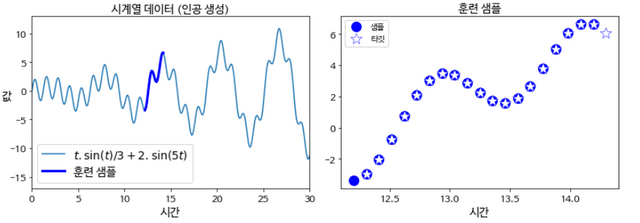
n_steps = 20
t_instance = np.linspace(12.2, 12.2 + resolution * (n_steps + 1), n_steps + 1)
plt.figure(figsize=(11,4))
plt.subplot(121)
plt.title("시계열 데이터 (인공 생성)", fontsize=14)
plt.plot(t, time_series(t), label=r"$t . \sin(t) / 3 + 2 . \sin(5t)$")
plt.plot(t_instance[:-1], time_series(t_instance[:-1]), "b-", linewidth=3, label="훈련 샘플")
plt.legend(loc="lower left", fontsize=14)
plt.axis([0, 30, -17, 13])
plt.xlabel("시간")
plt.ylabel("값", rotation=0)
plt.subplot(122)
plt.title("훈련 샘플", fontsize=14)
plt.plot(t_instance[:-1], time_series(t_instance[:-1]), "bo", markersize=12, label="샘플")
plt.plot(t_instance[1:], time_series(t_instance[1:]), "w*", markeredgewidth=0.5, markeredgecolor="b", markersize=14, label="타깃")
plt.legend(loc="upper left")
plt.xlabel("시간")
save_fig("time_series_plot")
plt.show()
RNN 하나를 만들어 보겠습니다. 이 신경망은 100개의 순환 뉴런을 가지고 있고
#각 훈련 샘플은 20개의 입력 길이로 구성되므로 20개의 타임 스텝에 펼칠 것입니다.
#각 입력은 하나의 특성을 가집니다(각 시간에서의 값 하나). 타깃도 20개의 입력 시퀀스이고 하나의 값을 가집니다:
reset_graph()
n_steps = 20
n_inputs = 1
n_neurons = 100
n_outputs = 1
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_steps, n_outputs])
cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu)
outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
각 타임 스텝에서 크기가 100인 출력 벡터가 만들어 집니다.
#하지만 각 타임 스텝에서 하나의 출력 값을 원합니다.
#간단한 방법은 OutputProjectionWrapper로 셀을 감싸는 것입니다.
reset_graph()
n_steps = 20
n_inputs = 1
n_neurons = 100
n_outputs = 1
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_steps, n_outputs])
cell = tf.contrib.rnn.OutputProjectionWrapper(
tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu),
output_size=n_outputs)
outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
learning_rate = 0.001
loss = tf.reduce_mean(tf.square(outputs - y)) # MSE
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_iterations = 1500
batch_size = 50
with tf.Session() as sess:
init.run()
for iteration in range(n_iterations):
X_batch, y_batch = next_batch(batch_size, n_steps)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
if iteration % 100 == 0:
mse = loss.eval(feed_dict={X: X_batch, y: y_batch})
print(iteration, "\tMSE:", mse)
saver.save(sess, "./my_time_series_model") # not shown in the book
with tf.Session() as sess: # 책에는 없음
saver.restore(sess, "./my_time_series_model") # 책에는 없음
X_new = time_series(np.array(t_instance[:-1].reshape(-1, n_steps, n_inputs)))
y_pred = sess.run(outputs, feed_dict={X: X_new})
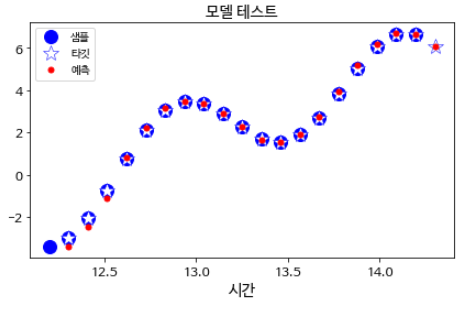
plt.title("모델 테스트", fontsize=14)
plt.plot(t_instance[:-1], time_series(t_instance[:-1]), "bo", markersize=12, label="샘플")
plt.plot(t_instance[1:], time_series(t_instance[1:]), "w*", markeredgewidth=0.5, markeredgecolor="b", markersize=14, label="타깃")
plt.plot(t_instance[1:], y_pred[0,:,0], "r.", markersize=10, label="예측")
plt.legend(loc="upper left")
plt.xlabel("시간")
save_fig("time_series_pred_plot")
plt.show()