Shannon Entropy explained to my mother

Claude Shannon: Could have been a playboy, chose to be a genius.
Image source: https://atomsandvoid.wordpress.com/
Introduction
In this article, we are going to dive into the information theory, the concept of "quantity of information" and how do we measure information.
I wrote this article in a way that anyone can understand this concept, its use and the logic behind it; so don't hesitate to comment if you think it can be improved or if you have questions.
I am not an expert nor a genius, not a professor nor a professionnal, just a passionate who can make mistakes; so take it just the way it is 😉
Are you ready ? Because today we dive into Shannon's entropy !! :D
Here's its basic definition:
"Shannon's Entropy is a mathematical function expressing the quantity of information delivered by an information source."
If you didn't understand anything, don't worry I'll explain every part of this definition.
In order to understand what it is, why it's beautiful and how to use it, I will explain you:
- Who is Claude Shannon and what he brung to the scientific world
- The "information quantity" concept and its mathematical model
- The "source of information" concept and its mathematical model
- The Shannon entropy, its formal definition and some exemples
- Some of the endless cases where it's usefull
- Sources
So let's get the party started !
Claude Shannon
Wikipedia tells:
Claude Elwood Shannon (April 30, 1916 – February 24, 2001) was an American mathematician, electrical engineer, and cryptographer known as "the father of information theory".
Shannon is noted for having founded information theory with a landmark paper, "A Mathematical Theory of Communication", that he published in 1948.
He is also well known for founding digital circuit design theory in 1937, when—as a 21-year-old master's degree student at the Massachusetts Institute of Technology (MIT) - he wrote his thesis demonstrating that electrical applications of Boolean algebra could construct any logical numerical relationship.
Shannon contributed to the field of cryptanalysis for national defense during World War II, including his fundamental work on codebreaking and secure telecommunications."
Yep. This man isn't Mickey Mouse. He is the father of information theory on which are based compression algorithm, network optimizations, file encodings, theorical computing, etc ...
He is the Newton of the computer science, without his work I couldn't have posted this on Steem 😥
He's mostly known for his book called "The Mathematical Theory of Communication" in which he creates mathematical models for communication, allowing mathematicians to build equations and formulas in order to optimize a system, quantify efficiency of a communication pipe, etc...
He created the base in which the whole computer science sphere we have today is standing.
Information quantity
An information quantity can be assimilated to the amount of knowledge you get from a state of knowledge A to a state of knowledge B.
Exemple:
There are balls in a box, 50 red, 50 blue and 50 green.
If someone pick a ball, I have the state of knowledge:
A = "The ball is either red, or blue, or green"
if I know the color C of this ball, I get to the state of knowledge:
B = "The color of the ball is C"
in order to find this color C, I have to ask 1 or 2 question of the following:
- "Is the ball red or not ?"
- "Is the ball blue or not ?"
- "Is the ball green or not ?"
If I try to guess the color of the ball without knowing anything, I have a success probability of 33%.
But if this person tells me that the ball isn't red, it raises my success probability to 50%.
This leads me to an intermediate state:
A2 = "The ball is either blue or green"
He added an additionnal 17% to my success rate.
If the tells me that the ball isn't blue, my success probability is 100%, I know it's green.
We reached the state:
B = "The color of the ball is green"
Because I had to ask 2 questions in order get a 100% success rate to my guess, the quantity of information related to the color of the ball equals to 2 "yes or no" questions about the ball's color.
Think about it as if you were reading an instructive book about a subject.
The first time you read about this subject, it will bring you a lot of information, you go from the state
"I don't know anything about cooking"
to
"I know some things about cooking".
But the more you read, the more you will find elements you already know, so it will be a lot harder to go to a higher state of information.
If we ask you a question about this subject, your probability to be able to answer this question will be linked to the amount of information you got from your books, no matter how many you've read.
If the quantity of information from a book A equals to 1, the quantity of information from some books A1 and A2 who says exactly the same thing as the book A but differently will still be 1.
However, if a book B explains things you never heard of in the book B, it will give you an additional quantity of information.
And this is how information quantity can be seen, the increase of your success rate to a test in a given frame.
If it's not clear yet, it is a bit like calories.
They are formally defined as a quantity of energy to heat a material from a temperature T1 to a temperature T2.
The information is the energy to go from knowledge K1 to knowledge K2.
Source of information
An information source is a random variable in probability.
It's a pipe which will output symbols; one at a time.
Exemples:
Pick a ball in a box with 50 red, 50 blue and 50 green balls.
If we say that
Red = 1; Blue = 2; Green = 3,
we have an information source which will deliver 1, 2 or 3 with a probability p(1) = 0.33, p(2) = 0.33, p(3) = 0.33.
Each information that will go off from the information source, this "pipe" will be the color of the ball in this case, expressed using symbols (here 1 for Red, 2 for Blue, etc ...)
Let's say we have the sentence "mommy made me my meal".
With the translation in numbers:
m = 1
o = 2
y = 3
a = 4
d = 5
e = 6
l = 7
I don't care about the space caracter, it's just simpler
If we pick a random letter in this sentence, we will have an information source X with:
p(X == 1) = 7/21 = 0.3333
p(X == 2) = 1/21 = 0.0476
p(X == 3) = 2/21 = 0.0952
p(X == 4) = 2/21 = 0.0952
p(X == 5) = 1/21 = 0.0476
p(X == 6) = 3/21 = 0.1428
p(X == 7) = 1/21 = 0.0476
In other words, the random letter picked in this phrase have:
33% of chance to be a "m"
4.7% of chance to be a "o"
9.5% of chance to be a "y"
etc ...
Let's consider the text
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
This is an information source, which will output one symbol, one letter, at a time. So here we'll have:
- X = "L", then
- X = "o", then
- X = "r", then
- X = "e", then
- etc ...
The "pipe" X will output one symbol each time we need, until we reach the end of the text, we can then compute probabilities formula and treat the data we receive in any way we want !
The concept of information source permit us to considerate any information
source as a random variable, allowing us to use every probabilities
theorems that involves random variables; this will stay mathematically
correct.
Shannon entropy
We've seen that a quantity of information can be assimilated to the increase of the success rate to a test in a given situation, and that an information source is a random variable which can be used in probabilities.
Now let's cross the knowledge we got from the last 2 parts.
Let's take back our sentence "mommy made me my meal".
We've seen the probabilities to get a given letter if we pick a random one in this text, but is the quantity of information the same for each letter in this text ?
How many questions will I have to ask in order to get a 100% success rate ?
To figure this out, let's use the Shannon entropy formula ! :D
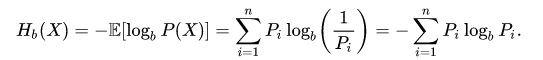
Hb(X): Shannon entropy of information source X in a given base b
n: Number of symbols (in our phrase there are 7 symbols)
b: Base of our numeric system (see explanation below)
Pi: Probability that the symbol i gets output from the information source
But what is this base thing in the equation ?
The base is the number of symbols we want our result to be expressed with, we usually use the base 2 because we can express the result in bits and it's similar to the case where we ask "Is it blue or not ?", True (1) or False (0).
We can express entropy in other bases depending on our situation
(I give an exemple in the "Use cases" section where I use base 4 instead of base 2)
So for this sentence "mommy made me my meal", we have an entropy of 2.203.
That means in average, we only have to ask 2.203 questions in order to guess the random symbol with a 100% success rate.
The more the Shannon entropy is high, the more we have incertitude about the next symbol that the output will produce (and the more we will have to ask in order to guess); the less the Shannon entropy is high, the more we are certain about the next symbol that the output will produce.
How we can use this result now:
If use this binary system to represent the letters:
- m: 0 (33.33% probability)
- e: 10 (14.28% probability)
- y: 110 (9.52% probability)
- a: 1110 (9.52% probability)
- o: 11110 (4.76% probability)
- d: 111110 (4.76% probability)
- l: 111111 (4.76% probability)
This notation can be compared to a serie of questions in which we write down answers from left to right, "0" if yes, "1" if no:
- "Is the letter a m ?"
Yes -> 0 -> Result is 0
No -> 1 - "Is the letter a e ?"
Yes -> 10 -> Result is 10
No -> 11 - "Is the letter a y ?"
Yes -> 110 -> Result is 110
No -> 111 - etc ...
- "Is the letter a d ?"
Yes -> 1111110 -> Result is 1111110
No -> 1111111 -> Result is 1111111
End of note
This way to represent our symbols is called the Huffman source coding, and we can except that the resulting size will be between
H×nchars < size < (H+1)×nchars
(Where "nchars" is the number of letters in our text, "H" its Shannon entropy and "size" its size in Huffman code).
Here we have a 17 letters long text, with a Shannon entropy of 2.203.
We can expect that the size will be greater than 37.451 bits and lower than 54.45 bits.
Results
"mommy made me my meal"
will be coded in
"01111000110011101111101001001100101110111111"
in Huffman coding, which is 44 bits long, all good !
Of course this is just the simpliest equation and use of the Shannon entropy but I let you discover more if you are interessed ;-)
Use cases
Encoding and compression
Well we've already seen an exemple just before, I said that using the Huffman source coding we can expect a size of H to H+1 bit / symbols, it is a way to rank coding methods and compression algorithm.
The Shannon entropy is the size's ultimate minimum of an information in a given base.
So the closer a compression algorithm or information encoding method goes near this limit, the better it is considered !
The ultimate limit of size without losing any information, some compression algorithm allows some information loss, like jpeg, mp3, etc ...
Storage size calculation
In the examples below, we used the binary base (base 2), but what if we want to store information on a piece of DNA ?
How much DNA we have to create ? How much will it cost ?
If we simplify the situation, we just go from a base 2 (1 and 0) to a base 4 (Adenine, Guanine, Cytosine and Thymine). So no worries !
Our Shannon entropy for the string "mommy made me my meal" in base 4 is 1.1015
Let's consider the coding:
m: T
e: CT
y: GT
a: AT
o: CCT
d: CGT
l: CAT
I don't know if it's the better way to code the letters, but we'll assume that it's as much efficient as Huffman's one.
If our encoding has the same performence as Huffman's one, we can expect
17×1.1015 < number of DNA elements < 17×(1+ 1.1015)
18.72 < number of DNA elements < 35.72
If the cost per DNA element is 5$, we will have to pay between 93.60$ and 178.62$.
Langage detection
Each langage has its own statistics (letter probability, letters repeat, word length, redundancy, etc...) so knowing the detailed statistics of a langage can lead to very specific entropy values; and then can be used as a fingerprint of a specific langage.
Anything can be used as an information source as long as we take the time to encode it to symbols.
We have the base data:
| Shannon entropy of | Letters | Length of words |
|---|---|---|
| Langage A | 6.29 | 4.21 |
| Langage B | 5.79 | 3.25 |
| Langage C | 6.90 | 2.56 |
If we then analyse an encrypted string using ROT13 (replace A with K, B with L, etc ...) and we got, after analysis:
| Shannon entropy of | Letters | Length of words |
|---|---|---|
| Unknown langage | 5.95 | 3.01 |
We can easily compute:
| Langage fit in % | Letters | Length of words | Total |
|---|---|---|---|
| A | 94.59% | 71.49% | 82.23% |
| B | 97.31% | 92.61% | 94.93% |
| C | 86.23% | 85.04% | 85.63% |
Knowing what the langage probably is, we can then try to identify basic words (like "the" or "I" in english) in order to get the clear message.
But it can be used as well for automatic langage detection in translator, websites scrapers, etc ...
Biology / Medecine
A study showed in 2001 that the Shannon entropy can be used to measure the effect of desflurane (used for anesthesia) on a patient.
They showed that the Shannon entropy was a good way to measure, using the records of an electroencephalograph, the volume of desflurane in the endtidal (end of breathing cycle).
Others
There are a lot of other fields I didn't talk about (Automatic guided vehicles, network-related uses, etc ...) and I let you search about all of this !
Aaaaaaaaand there is a Psychedelic Rock group who's named Shannon Entropy (and it's kinda great !)
-> https://www.shannonentropy.com/
Sources
- https://en.wikipedia.org/wiki/Entropy_(information_theory)
- https://math.stackexchange.com/questions/2299145/why-does-the-average-number-of-questions-bits-needed-for-storage-in-shannons-en
- (PDF) www.ueltschi.org/teaching/chapShannon.pdf
- https://towardsdatascience.com/demystifying-entropy-f2c3221e2550
- http://anesthesiology.pubs.asahq.org/Article.aspx?articleid=1944103
- https://en.wikipedia.org/wiki/Claude_Shannon
- http://users.fred.net/tds/lab/
- https://people.seas.harvard.edu/~jones/cscie129/papers/stanford_info_paper/entropy_of_english_9.htm
Sorry for my bad english, don't hesitate to correct me that'll help me improve :-)
Feel free to upvote, resteem, share, comment, this post or follow me for more awesome content ! 😎
Take care,
Warlkiry
To listen to the audio version of this article click on the play image.

Brought to you by @tts. If you find it useful please consider upvoting this reply.
Congratulations @warlkiry! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Congratulations @warlkiry! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!