[Week 2] Google IT Support Professional Certificate #31 | Course 5 IT Security: Defense against the digital dark arts {Part 2}
.jpg)
This is part 2 of week 2.For part 1 click here http://bit.ly/2x9ffgQ
7. Hashing
So far, we've talked about two forms of encryption, symmetric and asymmetric. In this next lesson, we're going to cover a special type of function that's widely used in computing and especially within security, hashing. No, not the breakfast kind, although those are delicious. Hashing or a hash function is a type of function or operation that takes in an arbitrary data input and maps it to an output of a fixed size, called a hash or a digest. The output size is usually specified in bits of data and is often included in the hashing function main. What this means exactly is that you feed in any amount of data into a hash function and the resulting output will always be the same size. But the output should be unique to the input, such that two different inputs should never yield the same output. Hash functions have a large number of applications in computing in general, typically used to uniquely identify data. You may have heard the term hash table before in context of software engineering. This is a type of data structure that uses hashes to accelerate data lookups. Hashing can also be used to identify duplicate data sets in databases or archives to speed up searching of tables or to remove duplicate data to save space. Depending on the application, there are various properties that may be desired, and a variety of hashing functions exist for various applications. We're primarily concerned with cryptographic hash functions which are used for various applications like authentication, message integrity, fingerprinting, data corruption detection and digital signatures. Cryptographic hashing is distinctly different from encryption because cryptographic hash functions should be one directional. They're similar in that you can input plain text into the hash function and get output that's unintelligible but you can't take the hash output and recover the plain text. The ideal cryptographic hash function should be deterministic, meaning that the same input value should always return the same hash value. The function should be quick to compute and be efficient. It should be infeasible to reverse the function and recover the plain text from the hash digest. A small change in the input should result in a change in the output so that there is no correlation between the change in the input and the resulting change in the output. Finally, the function should not allow for hash collisions, meaning two different inputs mapping to the same output. Cryptographic hash functions are very similar to symmetric key block ciphers and that they operate on blocks of data. In fact, many popular hash functions are actually based on modified block ciphers. Lets take a basic example to quickly demonstrate how a hash function works. We'll use an imaginary hash function for demonstration purposes. Lets say we have an input string of "Hello World" and we feed this into a hash function which generates the resulting hash of E49A00FF.

Every time we feed this string into our function, we get the same hash digest output. Now let's modify the input very slightly so it becomes "hello world", all lower case now. While this change seems small to us, the resulting hash output is wildly different, FF1832AE. Here is the same example but using a real hash function, in this case md5sum.
Hopefully, the concept of hash functions make sense to you now. In the next section, we will explore some examples of hashing algorithms and dive into weaknesses or attacks on hash functions.

8. Hashing Algorithms
In this section, we'll cover some of the more popular hashing functions, both currently and historically. MD5 is a popular and widely used hash function designed in the early 1990s as a cryptographic hashing function. It operates on a 512 bit blocks and generates 128 bit hash digests. While MD5 was published in 1992, a design flaw was discovered in 1996, and cryptographers recommended using the SHA-1 hash, a more secure alternative. But, this flaw was not deemed critical, so the hash function continued to see widespread use and adoption. In 2004, it was discovered that MD5 is susceptible to hash collisions, allowing for a bad actor to craft a malicious file that can generate the same MD5 digest as another different legitimate file. Bad actors are the worst, aren't they? Shortly after this flaw was discovered, security researchers were able to generate two different files that have matching MD5 hash digests. In 2008, security researchers took this a step further and demonstrated the ability to create a fake SSL certificate, that validated due to an empty five hash collision. Due to these very serious vulnerabilities in the hash function, it was recommended to stop using MD5 for cryptographic applications by 2010. In 2012, this hash collision was used for nefarious purposes in the flame malware, which used the forge Microsoft digital certificate to sign their malware, which resulted in the malware appearing to be from legitimate software that came from Microsoft. You can learn more about the flame malware in the next reading. When design flaws were discovered in MD5, it was recommended to use SHA-1 as a replacement. SHA-1 is part of the secure hash algorithm suite of functions, designed by the NSA and published in 1995. It operates a 512 bit blocks and generates 160 bit hash digest. SHA-1 is another widely used cryptographic hashing functions, used in popular protocols like TLS/SSL, PGP SSH, and IPsec. SHA-1 is also used in version control systems like Git, which uses hashes to identify revisions and ensure data integrity by detecting corruption or tampering. SHA-1 and SHA-2 were required for use in some US government cases for protection of sensitive information. Although, the US National Institute of Standards and Technology, recommended stopping the use of SHA-1 and relying on SHA-2 in 2010. Many other organizations have also recommended replacing SHA-1 with SHA-2 or SHA-3. And major browser vendors have announced intentions to drop support for SSL certificates that use SHA-1 in 2017. SHA-1 also has its share of weaknesses and vulnerabilities, with security researchers trying to demonstrate realistic hash collisions. During the 2000s, a bunch of theoretical attacks were formulated and some partial collisions were demonstrated, but full collisions using these methods requires significant computing power. One such attack was estimated to require $2.77 million in cloud computing CPU resources, Wowza. In 2015, a different attack method was developed that didn't demonstrate a full collision but this was the first time that one of these attacks was demonstrated which had major implications for the future security of SHA-1. What was only theoretically possible before, was now becoming possible with more efficient attack methods and increases in computing performance, especially in the space of GPU accelerated computations in cloud resources. A full collision with this attack method was estimated to be feasible using CPU and GPU cloud computing for approximately $75 to $120,000 , much cheaper than previous attacks. You can read more about these attacks and collisions in the next reading. In early 2017, the first full collision of SHA-1 was published. Using significant CPU and GPU resources, two unique PDF files were created that result in the same SHA-1 hash. The estimated processing power required to do this was described as equivalent of 6,500 years of a single CPU, and 110 years of a single GPU computing non-stop. That's a lot of years. There's also the concept of a MIC, or message integrity check. This shouldn't be confused with a MAC or message authentication check, since how they work and what they protect against is different. A MIC is essentially a hash digest of the message in question. You can think of it as a check sum for the message, ensuring that the contents of the message weren't modified in transit. But this is distinctly different from a MAC that we talked about earlier. It doesn't use secret keys, which means the message isn't authenticated. There's nothing stopping an attacker from altering the message, recomputing the checksum, and modifying the MIC attached to the message. You can think of MICs as protecting against accidental corruption or loss, but not protecting against tampering or malicious actions.
During the 2000s, a bunch of theoretical attacks against SHA1 were formulated and some partial collisions were demonstrated. In early 2017, the first full collision of SHA1 was published.
https://eprint.iacr.org/2005/010
https://www.schneier.com/blog/archives/2005/02/sha1_broken.html
https://eprint.iacr.org/2007/474
https://shattered.io/
9. Hashing Algorithms (continued)
We've already alluded to attacks on hashes. Now let's learn more details, including how to defend against these attacks. One crucial application for cryptographic hash functions is for authentication. Think about when you log into your e-mail account. You enter your e-mail address and password. What do you think happens in the background for the e-mail system to authenticate you? It has to verify that the password you entered is the correct one for your account. You could just take the user supplied password and look up the password on file for the given account and compare them. Right? If they're the same, then the user is authenticated. Seems like a simple solution but does that seem secure to you? In the authentication scenario, we'd have to store user passwords in plain text somewhere. That's a terrible idea. You should never ever store sensitive information like passwords in plain text. Instead, you should do what pretty much every authentication system does, store a hash of the password instead of the password itself. When you log into your e-mail account the password you entered is run through the hashing function and then the resulting hash digest is compared against the hash on file. If the hashes match, then we know the password is correct, and you're authenticated. Password shouldn't be stored in plain text because if your systems are compromised, passwords for other accounts are ultimate prize for the attacker. If an attacker manages to gain access to your system and can just copy the database of accounts and passwords, this would obviously be a bad situation. By only storing password hashes, the worst the attacker would be able to recover would be password hashes, which aren't really useful on their own. What if the attacker wanted to figure out what passwords correspond to the hashes they stole? They would perform a brute force attack against the password hash database. This is where the attacker just tries all possible input values until the resulting hash matches the one they're trying to recover the plain text for. Once there's a match, we know that the input that's generated that matches the hash is the corresponding password. As you can imagine, a brute force attack can be very computationally intensive depending on the hashing function used. An important characteristic to call out about brute force attacks is, technically, they're impossible to protect against completely. A successful brute force attack against even the most secure system imaginable is a function of attacker time and resources. If an attacker has unlimited time and or resources any system can be brute force. Yikes. The best we can do to protect against these attacks, is to raise the bar. Make it sufficiently time and resource intensive so that it's not practically feasible in a useful timeframe or with existing technology. Another common method to help raise the computational bar and protect against brute force attacks is to run the password through the hashing function multiple times, sometimes through thousands of interactions. This would require significantly more computations for each password guess attempt. That brings us to the topic of rainbow tables. Don't be fooled by the colorful name. These tables are used by bad actors to help speed up the process of recovering passwords from stolen password hashes. A rainbow table is just a pre-computed table of all possible password values and their corresponding hashes.

The idea behind rainbow table attacks is to trade computational power for disk space by pre-computing the hashes and storing them in a table. An attacker can determine what the corresponding password is for a given hash by just looking up the hash in their rainbow table. This is unlike a brute force attack where the hash is computed for each guess attempt. It's possible to download rainbow tables from the internet for popular password lists and hashing functions. This further reduces the need for computational resources requiring large amounts of storage space to keep all the password and hash data. You may be wondering how you can protect against these pre-computed rainbow tables. That's where salts come into play. And no, I'm not talking about table salt. A password salt is additional randomized data that's added into the hashing function to generate the hash that's unique to the password and salt combination. Here's how it works. A randomly chosen large salt is concatenated or tacked onto the end of the password. The combination of salt and password is then run through the hashing function to generate hash which is then stored alongside the salt. What this means now for an attacker is that they'd have to compute a rainbow table for each possible salt value.
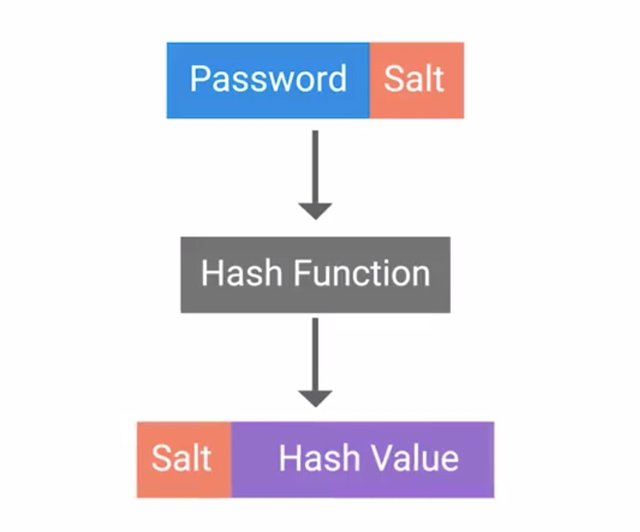
If a large salt is used, the computational and storage requirements to generate useful rainbow tables becomes almost unfeasible. Early Unix systems used a 12 Bit salt, which amounts to a total of 4,096 possible salts. So, an attacker would have to generate hashes for every password in their database, 4,096 times over. Modern systems like Linux, BSD and Solaris use a 128 bit salt. That means there are two to the 128 power possible salt values, which is over 340 undecillion. That's 340 with 36 zeros following. Clearly, 128 bit salt raises the bar high enough that a rainbow table attack wouldn't be possible in any realistic time-frame. Just another scenario when adding salt to something makes it even better. That runs out our lesson on hashing functions. Up next we'll talk about real world applications of cryptography and explain how it's used in various applications and protocols.
10. Public Key Infrastructure
In this lesson, we're going to cover PKI, or Public Key Infrastructure. Spoiler alert, this is a critical piece to securing communications on the Internet today. Earlier we talked about Public Key Cryptography and how it can be used to securely transmit data over an untrusted channel and verify the identity of a sender using digital signatures. PKI is a system that defines the creation, storage and distribution of digital certificates. A digital certificate is a file that proves that an entity owns a certain public key. A certificate contains information about the public key, the entity it belongs to and a digital signature from another party that has verified this information.

If the signature is valid and we trust the entity that signed the certificate, then we can trust the public key to be used to securely communicate with the entity that owns it. The entity that's responsible for storing, issuing, and signing certificates is referred to as CA, or Certificate Authority. It's a crucial component of the PKI system. There's also an RA, or Registration Authority, that's responsible for verifying the identities of any entities requesting certificates to be signed and stored with the CA. This role is usually lumped together with the CA. A central repository is needed to securely store and index keys and a certificate management system of some sort makes managing access to storage certificates and issuance of certificates easier. There are a few different types of certificates that have different applications or uses. The one you're probably most familiar with is SSL or TLS server certificate. This is a certificate that a web server presents to a client as part of the initial secure setup of an SSL, TLS connection. Don't worry, we'll cover SSL, TLS in more detail in a future lesson. The client usually a web browser will then verify that the subject of the certificate matches the host name of the server the client is trying to connect to. The client will also verify that the certificate is signed by a certificate authority that the client trusts. It's possible for a certificate to be valid for multiple host names. In some cases, a wild card certificate can be issued where the host name is replaced with an asterisk, denoting validity for all host names within a domain. It's also possible for a server to use what's called a Self Sign Certificate. You may have guessed from the name. This certificate has been signed by the same entity that issued the certificate. This would basically be signing your own public key using your private key. Unless you already trusted this key, this certificate would fail to verify. Another certificate type is an SSL or TLS client certificate. This is an optional component of SSL, TLS connections and is less commonly seen than server certificates. As the name implies, these are certificates that are bound to clients and are used to authenticate the client to the server, allowing access control to a SSL, TLS service. These are different from server certificates in that the client certificates aren't issued by a public CA. Usually the service operator would have their own internal CA which issues and manages client certificates for their service. There are also code signing certificates which are used for signing executable programs. This allows users of these signed applications to verify the signatures and ensure that the application was not tampered with. It also lets them verify that the application came from the software author and is not a malicious twin. We've mentioned certificate authority trust, but not really explained it. So let's take some time to go over how it all works. PKI is very much dependent on trust relationships between entities, and building a network or chain of trust. This chain of trust has to start somewhere and that starts with the Root Certificate Authority. These root certificates are self signed because they are the start of the chain of trust. So there's no higher authority that can sign on their behalf.
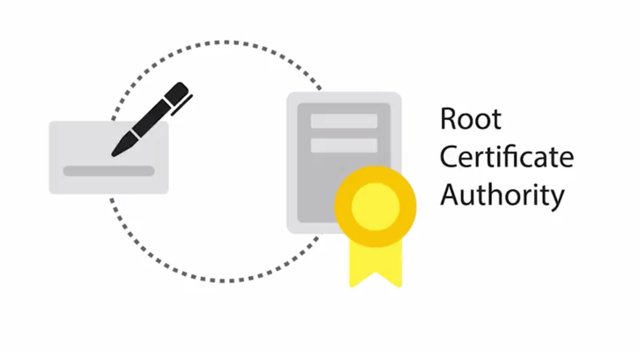
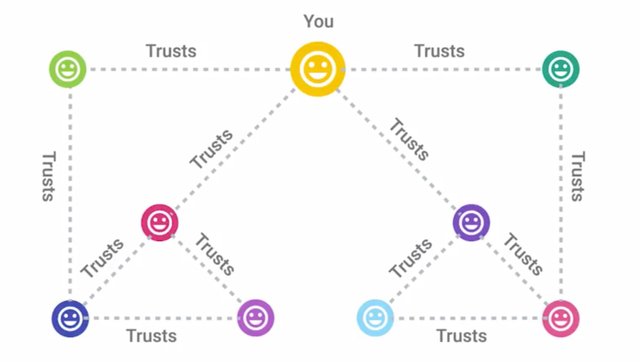
This Root Certificate Authority can now use the self-signed certificate and the associated private key to begin signing other public keys and issuing certificates. It builds a sort of tree structure with the root private key at the top of the structure. If the root CA signs a certificate and sets a field in the certificate called CA to true, this marks a certificate as an intermediary or subordinate CA. What this means is that the entity that this certificate was issued to can now sign other certificates. And this CA has the same trust as the root CA. An intermediary CA can also sign other intermediate CAs. You can see how this extension of trust from one root CA to intermediaries can begin to build a chain. A certificate that has no authority as a CA is referred to as an End Entity or Leaf Certificate. Similar to a leaf on a tree, it's the end of the tree structure and can be considered the opposite of the roots. You might be wondering how these root CAs wind up being trusted in the first place. Well, that's a very good question. In order to bootstrap this chain of trust, you have to trust a root CA certificate, otherwise the whole chain is untrusted. This is done by distributing root CA certificates via alternative channels. Each major OS vendor ships a large number of trusted root CA certificates with their OS. And they typically have their own programs to facilitate distribution of root CA certificates. Most browsers will then utilize the OS provided store of root certificates. Let's do a deep dive into certificates beyond just their function. The X.509 standard is what defines the format of digital certificates. It also defines a certificate revocation list or CRL which is a means to distribute a list of certificates that are no longer valid. The X.509 standard was first issued in 1988 and the current modern version of the standard is version 3. The fields defined in X.509 certificate are, the version, what version of the X.509 standard certificate adheres to. Serial number, a unique identifier for their certificate assigned by the CA which allows the CA to manage and identify individual certificates. Certificate Signature Algorithm, this field indicates what public key algorithm is used for the public key and what hashing algorithm is used to sign the certificate. Issuer Name, this field contains information about the authority that signed the certificate. Validity, this contains two subfields, Not Before and Not After, which define the dates when the certificate is valid for. Subject, this field contains identifying information about the entity the certificate was issued to. Subject Public Key Info, these two subfields define the algorithm of the public key along with the public key itself. Certificate signature algorithm, same as the Subject Public Key Info field, these two fields must match. Certificate Signature Value, the digital signature data itself. There are also certificate fingerprints which aren't actually fields in the certificate itself, but are computed by clients when validating or inspecting certificates. These are just hash digests of the whole certificate. You can read about the full X.509 standard in the next reading. And alternative to the centralized PKI model of establishing trust and binding identities is what's called the Web of Trust. A Web of Trust is where individuals instead of certificate authorities sign other individuals' public keys. Before an individual signs a key, they should first verify the person's identity through an agreed upon mechanism. Usually by checking some form of identification, driver's license, passport, etc. Once they determine the person is who they claim to be, signing their public key is basically vouching for this person. You're saying that you trust that this public key belongs to this individual. This process would be reciprocal, meaning both parties would sign each other's keys. Usually people who are interested in establishing web of trust will organize what are called Key Signing Parties where participants performed the same verification and signing. At the end of the party everyone's public key should have been signed by every other participant establishing a web of trust. In the future when one of these participants in the initial key signing party establishes trust with a new member, the web of trust extends to include this new member and other individuals they also trust. This allows separate webs of trust to be bridged by individuals and allows the network of trust to grow.
The X.509 standard is what defines the format of digital certificates.
https://www.ietf.org/rfc/rfc5280.txt
11. Cryptography in Action
In this section, we'll dive into some real world applications of the encryption concepts that we've covered so far. In the last section, we mentioned SSL/TLS when we were talking about digital certificates. Now that we understand how digital certificates function and the crucial roles CAs play, let's check out how that fits into securing web traffic via HTTPS. You've probably heard of HTTPS before, but do you know exactly what it is and how it's different from HTTP?
Very simply, HTTPS is the secure version of HTTP, the Hypertext Transfer Protocol. So how exactly does HTTPS protect us on the Internet? HTTPS can also be called HTTP over SSL or TLS since it's essentially encapsulating the HTTP traffic over an encrypted, secured channel utilizing SSL or TLS. You might hear SSL and TLS used interchangeably, but SSL 3.0, the latest revision of SSL, was deprecated in 2015, and TLS 1.2 is the current recommended revision, with version 1.3 still in the works. Now, it's important to call out that TLS is actually independent of HTTPS, and is actually a generic protocol to permit secure communications and authentication over a network. TLS is also used to secure other communications aside from web browsing, like VoIP calls such as Skype or Hangouts, email, instant messaging, and even Wi-Fi network security. TLS grants us three things. One, a secure communication line, which means data being transmitted is protected from potential eavesdroppers. Two, the ability to authenticate both parties communicating, though typically, only the server is authenticated by the client. And three, the integrity of communications, meaning there are checks to ensure that messages aren't lost or altered in transit. TLS essentially provides a secure channel for an application to communicate with a service, but there must be a mechanism to establish this channel initially. This is what's referred to as a TLS handshake. I'm more of a high five person myself, but we can move on. The handshake process kicks off with a client establishing a connection with a TLS enabled service, referred to in the protocol as ClientHello.
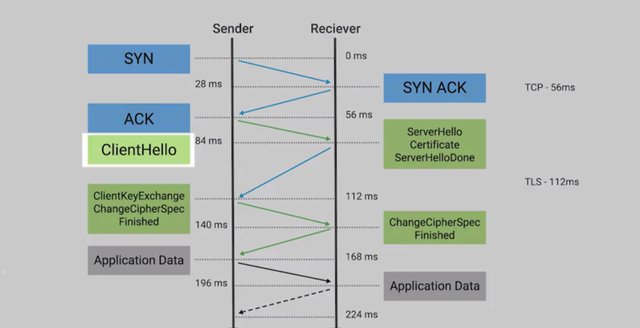
This includes information about the client, like the version of the TLS that the client supports, a list of cipher suites that it supports, and maybe some additional TLS options. The server then responds with a ServerHello message, in which it selects the highest protocol version in common with the client, and chooses a cipher suite from the list to use. It also transmits its digital certificate and a final ServerHelloDone message. The client will then validate the certificate that the server sent over to ensure that it's trusted and it's for the appropriate host name. Assuming the certificate checks out, the client then sends a ClientKeyExchange message. This is when the client chooses a key exchange mechanism to securely establish a shared secret with the server, which will be used with a symmetric encryption cipher to encrypt all further communications. The client also sends a ChangeCipherSpec message indicating that it's switching to secure communications now that it has all the information needed to begin communicating over the secure channel. This is followed by an encrypted Finished message which also serves to verify that the handshake completed successfully.
The server replies with a ChangeCipherSpec and an encrypted Finished message once the shared secret is received. Once complete, application data can begin to flow over the now the secured channel. High five to that. The session key is the shared symmetric encryption key using TLS sessions to encrypt data being sent back and forth. Since this key is derived from the public-private key, if the private key is compromised, there's potential for an attacker to decode all previously transmitted messages that were encoded using keys derived from this private key.
To defend against this, there's a concept of forward secrecy. This is a property of a cryptographic system so that even in the event that the private key is compromised, the session keys are still safe. The SSH, or secure shell, is a secure network protocol that uses encryption to allow access to a network service over unsecured networks. Most commonly, you'll see SSH use for remote login to command line base systems, but the protocol is super flexible and has provisions for allowing arbitrary networks and traffic over those ports to be tunneled over the encrypted channel. It was originally designed as a secure replacement for the Telnet protocol and other unsecured remote login shell protocols like rlogin or r-exec. It's very important that remote login and shell protocols use encryption. Otherwise, these services will be transmitting usernames and passwords, along with keystrokes and terminal output in plain text. This opens up the possibility for an eavesdropper to intercept credentials and keystrokes, not good. SSH uses public key cryptography to authenticate the remote machine that the client is connecting to, and has provisions to allow user authentication via client certificates, if desired. The SSH protocol is very flexible and modular, and supports a wide variety of different key exchange mechanisms like Diffie-Hellman, along with a variety of symmetric encryption ciphers. It also supports a variety of authentication methods, including custom ones that you can write. When using public key authentication, a key pair is generated by the user who wants to authenticate. They then must distribute those public keys to all systems that they want to authenticate to using the key pair. When authenticating, SSH will ensure that the public key being presented matches the private key, which should never leave the user's possession.
PGP stands for Pretty Good Privacy. How's that for a creative name? Well, PGP is an encryption application that allows authentication of data along with privacy from third parties relying upon asymmetric encryption to achieve this. It's most commonly used for encrypted email communication, but it's also available as a full disk encryption solution or for encrypting arbitrary files, documents, or folders. PGP was developed by Phil Zimmerman in 1991 and it was freely available for anyone to use. The source code was even distributed along with the software. Zimmerman was an anti nuclear activist, and political activism drove his development of the PGP encryption software to facilitate secure communications for other activists. PGP took off once released and found its way around the world, which wound up getting Zimmerman into hot water with the US federal government. At the time, US federal export regulations classified encryption technology that used keys larger than 40 bits in length as munitions. This meant that PGP was subject to similar restrictions as rockets, bombs, firearms, even nuclear weapons. PGP was designed to use keys no smaller than 128-bit, so it ran up against these export restrictions, and Zimmerman faced a federal investigation for the widespread distribution of his cryptographic software. Zimmerman took a creative approach to challenging these restrictions by publishing the source code in a hardcover printed book which was made available widely. The idea was that the contents of the book should be protected by the first amendment of the US constitution. Pretty clever? The investigation was eventually closed in 1996 without any charges being filed, and Zimmerman didn't even need to go to court. You can read more about why he developed PGP in the next reading. PGP is widely regarded as very secure, with no known mechanisms to break the encryption via cryptographic or computational means. It's been compared to military grade encryption, and there are numerous cases of police and government unable to recover data protected by PGP encryption. In these cases, law enforcement tend to resort to legal measure to force the handover of passwords or keys. Originally, PGP used the RSA algorithm, but that was eventually replaced with DSA to avoid issues with licensing.
PGP was developed by Phil Zimmermann in 1991 and was freely available for anyone to use.
http://www.philzimmermann.com/EN/essays/WhyIWrotePGP.html
12. Securing Network Traffic
Let's talk about securing network traffic. As we've seen, encryption is used for protecting data both from the privacy perspective and the data integrity perspective. A natural application of this technology is to protect data in transit, but what if our application doesn't utilize encryption? Or what if we want to provide remote access to internal resources too sensitive to expose directly to the Internet? We use a VPN, or Virtual Private Network solution. A VPN is a mechanism that allows you to remotely connect a host or network to an internal private network, passing the data over a public channel, like the Internet. You can think of this as a sort of encrypted tunnel where all of our remote system's network traffic would flow, transparently channeling our packets via the tunnel through the remote private network. A VPN can also be point-to-point, where two gateways are connected via a VPN. Essentially bridging two private networks through an encrypted tunnel.
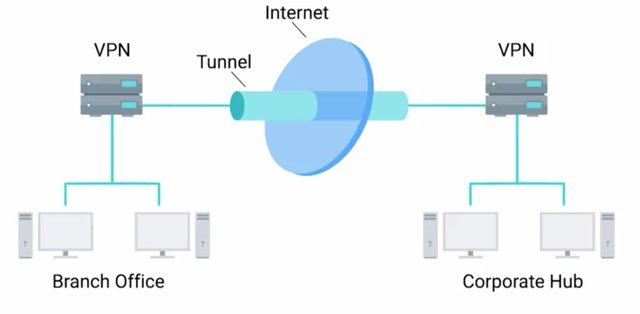
There are a bunch of VPN solutions using different approaches and protocols with differing benefits and tradeoffs. Let's go over some of the more popular ones. IPsec, or Internet Protocol Security, is a VPN protocol that was designed in conjunction with IPv6. It was originally required to be standards compliant with IPv6 implementations, but was eventually dropped as a requirement. It is optional for use with IPv6. IPsec works by encrypting an IP packet and encapsulating the encrypted packet inside an IPsec packet.
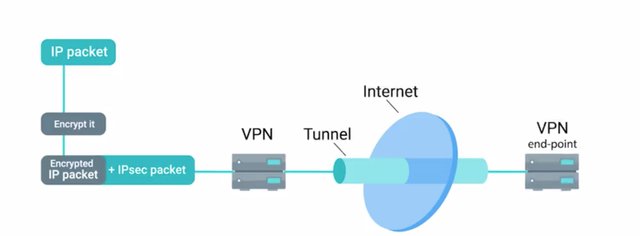
This encrypted packet then gets routed to the VPN endpoint where the packet is de-encapsulated and decrypted then sent to the final destination. IPsec supports two modes of operations, transport mode and tunnel mode. When transport mode is used, only the payload of the IP packet is encrypted, leaving the IP headers untouched. Heads up that authentication headers are also used. Header values are hashed and verified, along with the transport and application layers. This would prevent the use of anything that would modify these values, like NAT or PAT. In tunnel mode, the entire IP packet, header, payload, and all, is encrypted and encapsulated inside a new IP packet with new headers. While not a VPN solution itself, L2TP, or Layer 2 Tunneling Protocol, is typically used to support VPNs. A common implementation of L2TP is in conjunction with IPsec when data confidentially is needed, since L2TP doesn't provide encryption itself. It's a simple tunneling protocol that allows encapsulation of different protocols or traffic over a network that may not support the type of traffic being sent. L2TP can also just segregate and manage the traffic. ISPs will use the L2TP to deliver network access to a customer's endpoint, for example. The combination of L2TP and IPsec is referred to as L2TP IPsec and was officially standardized in ietf RFC 3193. The establishment of an L2TP IPsec connection works by first negotiating an IPsec security association. Which negotiates the details of the secure connection, including key exchange, if used. It can also share secrets, public keys, and a number of other mechanisms. I've included a link to more info about it in the next reading. Next, secure communication is established using Encapsulating Security Payload. It's a part of the IPsec suite of protocols, which encapsulates IP packets, providing confidentiality, integrity, and authentication of the packets. Once secure encapsulation has been established, negotiation and establishment of the L2TP tunnel can proceed. L2TP packets are now encapsulated by IPsec, protecting information about the private internal network. An important distinction to make in this setup is the difference between the tunnel and the secure channel. The tunnel is provided by L2TP, which permits the passing of unmodified packets from one network to another. The secure channel, on the other hand, is provided by IPsec, which provides confidentiality, integrity, and authentication of data being passed. SSL TLS is also used in some VPN implementations to secure network traffic, as opposed to individual sessions or connections. An example of this is OpenVPN, which uses the OpenSSL library to handle key exchange and encryption of data, along with control channels. This also enables OpenVPN to make use of all the cyphers implemented by the OpenSSL library. Authentication methods supported are pre-shared secrets, certificate-based, and username password. Certificate-based authentication would be the most secure option, but it requires more support and management overhead since every client must have a certificate. Username and password authentication can be used in conjunction with certificate authentication, providing additional layers of security. It should be called out that OpenVPN doesn't implement username and password authentication directly. It uses modules to plug into authentication systems, which we'll cover in the next module. OpenVPN can operate over either TCP or UDP, typically over port 1194. It supports pushing network configuration options from the server to a client and it supports two interfaces for networking. It can either rely on a Layer 3 IP tunnel or a Layer 2 Ethernet tap. The Ethernet tap is more flexible, allowing it to carry a wider range of traffic. From the security perspective, OpenVPN supports up to 256-bit encryption through the OpenSSL library. It also runs in user space, limiting the seriousness of potential vulnerabilities that might be present. There are a lot of acronyms to take in, so take a minute to go over them.
The combination of L2TP and IPsec is referred to as L2TP/IPsec and was officially standardized in IETF RFC 3193. https://tools.ietf.org/html/rfc3193
An example of this is OpenVPN, which uses the OpenSSL library to handle key exchange and encryption of data along with control channels.
https://openvpn.net/index.php/open-source.html
13. Cryptographic Hardware
Welcome back. Let's dive right in. Another interesting application of cryptography concepts, is the Trusted Platform Module or TPM. This is a hardware device that's typically integrated into the hardware of a computer, that's a dedicated crypto processor. TPM offers secure generation of keys, random number generation, remote attestation, and data binding and sealing.

A TPM has unique secret RSA key burned into the hardware at the time of manufacture, which allows a TPM to perform things like hardware authentication. This can detect unauthorized hardware changes to a system. Remote attestation is the idea of a system authenticating its software and hardware configuration to a remote system. This enables the remote system to determine the integrity of the remote system. This can be done using a TPM by generating a secure hash of the system configuration, using the unique RSA key embedded in the TPM itself. Another use of this secret hardware backed encryption key is data binding and sealing. It involves using the secret key to derive a unique key that's then used for encryption of data. Basically, this binds encrypted data to the TPM and by extension, the system the TPM is installed in, sends only the keys stored in hardware in the TPM will be able to decrypt the data. Data sealing is similar to binding since data is encrypted using the hardware backed encryption key. But, in order for the data to be decrypted, the TPM must be in a specified state. TPM is a standard with several revisions that can be implemented as a discrete hardware chip, integrated into another chip in a system, implemented in firmware software or virtualize then a hypervisor. The most secure implementation is the discrete chip, since these chip packages also incorporate physical tamper resistance to prevent physical attacks on the chip. Mobile devices have something similar referred to as a secure element. Similar to a TPM, it's a tamper resistant chip often embedded in the microprocessor or integrated into the mainboard of a mobile device. It supplies secure storage of cryptographic keys and provides a secure environment for applications. An evolution of secure elements is the Trusted Execution Environment or TEE which takes the concept a bit further. It provides a full-blown isolated execution environment that runs alongside the main OS. This provides isolation of the applications from the main OS and other applications installed there. It also isolates secure processes from each other when running in the TEE. TPMs have received criticism around trusting the manufacturer. Since the secret key is burned into the hardware at the time of manufacture, the manufacturer would have access to this key at the time. It is possible for the manufacturer to store the keys that could then be used to duplicate a TPM, that could break the security the module is supposed to provide. There's been one report of a physical attack on a TPM which allowed a security researcher to view and access the entire contents of a TPM. But this attack required the use of an electron microscope and micron precision equipment for manipulating a TPM circuitry. While the process was incredibly time intensive and required highly specialized equipment, it proved that such an attack is possible despite the tamper protections in place. . TPMs are most commonly used to ensure platform integrity, preventing unauthorized changes to the system either in software or hardware, and full disk encryption utilizing the TPM to protect the entire contents of the disk. Full Disk Encryption or FDE, as you might have guessed from the name, is the practice of encrypting the entire drive in the system. Not just sensitive files in the system. This allows us to protect the entire contents of the disk from data theft or tampering. Now, there are a bunch of options for implementing FDE. Like the commercial product PGP, Bitlocker from Microsoft, which integrates very well with TPMs, Filevault 2 from Apple, and the open source software dm-crypt, which provides encryption for Linux systems. An FDE configuration will have one partition or logical partition that holds the data to be encrypted. Typically, the root volume, where the OS is installed. But, in order for the volume to be booted, it must first be unlocked at boot time. Because the volume is encrypted, the BIOS can't access data on this volume for boot purposes. This is why FDE configurations will have a small unencrypted boot partition that contains elements like the kernel, bootloader and a netRD. At boot time, these elements are loaded which then prompts the user to enter a passphrase to unlock the disk and continue the boot process.

FDE can also incorporate the TPM, utilizing the TPM encryption keys to protect the disk. And, it has platform integrity to prevent unlocking of the disk if the system configuration is changed. This protects against attacks like hardware tampering, and disk theft or cloning. Before we wrap up this module on encryption, I wanted to touch base on the concept of random. Earlier, when we covered the various encryption systems, one commonality kept coming up that these systems rely on. Did you notice what it was? That's okay if you didn't. It's the selection of random numbers. This is a very important concept in encryption because if your number selection process isn't truly random, then there can be some kind of pattern that an adversary can discover through close observation and analysis of encrypted messages over time. Something that isn't truly random is referred to as pseudo-random. It's for this reason that operating systems maintain what's referred to as an entropy pool. This is essentially a source of random data to help seed random number generators. There's also dedicated random number generators and pseudo-random number generators, that can be incorporated into a security appliance or server to ensure that truly random numbers are chosen when generating cryptographic keys. I hope you found these topics in cryptography interesting and informative. I know I did when I first learned about them. In the next module, we'll cover the three As of security, authentication, authorization and accounting. These three As are awesome and I'll tell you why in the next module. But before we get there, one final quiz on the cryptographic concept we've covered so far.
here’s been one report of a physical attack on a TPM which allowed a security researcher to view and access the entire contents of a TPM.
https://gcn.com/Articles/2010/02/02/Black-Hat-chip-crack-020210.aspx
To Join this course click on the link below
.jpg)
Google IT Support Professional Certificate http://bit.ly/2JONxKk
LInks to previous weeks Courses.
[Week 1] Google IT Support Professional Certificate #29 | Course 5 IT Security: Defense against the digital dark arts
http://bit.ly/2x8hulk
Google IT Support Professional Certificate #0 | Why you should do this Course? | All details before you join this course.
http://bit.ly/2Oe2t8p
#steemiteducation #Computerscience #education #Growwithgoogle #ITskills #systemadministration #itprofessional
#googleitsupportprofessional
Atlast If you are interested in the IT field, this course, or want to learn Computer Science. If you want to know whats in this course, what skills I learned Follow me @hungryengine. I will guide you through every step of this course and share my knowledge from this course daily.
Support me on this journey and I will always provide you with some of the best career knowledge in Computer Science field.

This is part 1 of Week 2 .For Part 2 Click here
To Join this course click on the link below
Google IT Support Professional Certificate http://bit.ly/2JONxKk
LInks to previous weeks Courses.
[Week 1] Google IT Support Professional Certificate #29 | Course 5 IT Security: Defense against the digital dark arts
http://bit.ly/2x8hulk
Google IT Support Professional Certificate #0 | Why you should do this Course? | All details before you join this course.
http://bit.ly/2Oe2t8p
#steemiteducation #Computerscience #education #Growwithgoogle #ITskills #systemadministration #itprofessional
#googleitsupportprofessional
Atlast If you are interested in the IT field, this course, or want to learn Computer Science. If you want to know whats in this course, what skills I learned Follow me @hungryengine. I will guide you through every step of this course and share my knowledge from this course daily.
Support me on this journey and I will always provide you with some of the best career knowledge in Computer Science field.