Natural Language Text Analysis of most Up voted and Down voted posts in December 2017

Scope of Analysis
This analysis is a follow-on to prior work that examined text and emoji in several Categories (tags). This analysis differs in that we are focusing on the most loved posts (most Up Voted) and the least loved posts (most Flagged or Down Voted).
We will be considering data across all categories for the month of December 2017. This will include foreign languages and character sets.
Tools
This analysis is done with R and RStudio on an ailing 10 year old MacBook.
Extracting Data
We extract our data from Steemdata.com with this mongodb query and bring our data into the R analysis platform.
Extract Raw Posts
mdb <- mongo(collection="Posts",db="SteemData",url="mongodb://steemit:[email protected]:27017/SteemData")
raw1<- mdb$find(query='{"created": {"$gte": {"$date": "2017-12-01T00:00:00.00Z"}, "$lte": {"$date": "2017-12-31T00:00:00.00Z"} } }', fields='{"_id":0, "body":1, "net_votes":1}')
Extract Post Categories
mdb <- mongo(collection="Posts",db="SteemData",url="mongodb://steemit:[email protected]:27017/SteemData")
cats<- paste('[{ "$match": {"created": {"$gte": {"$date": "2017-12-01T00:00:00.00Z"}, "$lte": {"$date": "2017-12-30T00:00:00.00Z"} } } },{ "$group": { "_id": { "category" : "$category" }, "Post Count" : {"$sum" : 1 } } }, { "$project": {"_id": 0, "category": "$_id.category" , "Post Count" : 1 } } , { "$sort": { "Post Count": -1 } }]', sep="")
categories<- mdb$aggregate(cats)
Extracting the raw Post data took 1042.627 seconds and returned 856,438 Posts from 36,170 categories by 61,228 distinct users.
We see the most up voted post belonged to @sweetsssj for her bi-lingual travel post. She has clearly invested heavily in well edited narrative and high quality, well taken photos. She also engages extensively with her followers via comments.
On the other end of the spectrum the most downvoted post belonged to @infoshare222 with this repost of a rather dark YouTube video about the Free Masons.
These two examples represent the far ends of the content spectrum.
Target Selection
Assessing the distribution of votes we can focus in on the top decile (90th percentile or top 10%) and bottom deciles (10th percentile or bottom 10%).
Standard Deviation: 49.69996
Quantiles:
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
-57 0 1 2 3 4 6 9 15 34 2823
Summary Statistics:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-57.00 2.00 4.00 16.54 12.00 2823.00
Subsetting Good and Bad Posts
Next we will subset our data into two datasets. The Top dataset will include posts with more than 34 up votes each (90th percentile boundary). The Bottom dataset will include those with zero or negative votes.
top <- raw1[raw1[, "net_votes"] > 34, ]
bot <- raw1[raw1[, "net_votes"] < 0, ]
The Top dataset now include 83,799 Posts with more than 34 up votes. This dataset is approximately 234MB in size. The top 3 most prolific users by post count in this Top Most Up Voted Category are,
| User | Posts |
|---|---|
| @jout | 323 |
| @barrydutton | 320 |
| @tisantana | 288 |
The Bottom dataset now includes 18,540 Posts with zero or negative votes. This is approximately 67MB and one third the size of the Top dataset. The top 3 most prolific users by post count in this Bottom Most Down Voted Category are,
| User | Posts |
|---|---|
| @neocoinalert | 1309 |
| @rippleinfo | 1153 |
| @privacycoinsnews | 1150 |
These two dataset will now be loaded into a Corpus; a data structure designed specifically for text analysis.
Note: I am performing some minor data manipulation to make it a little easier to work with later in the processing pipeline.
# Top Corpus1
cps1 <- as.data.frame(top)
cps1$id <- seq.int(nrow(cps1))
colnames(cps1) <- c("text", "id")
cps1 <- cps1[c("id", "text")]
Corpus1 <- quanteda::corpus(cps1)
# Bot Corpus1
cps2 <- as.data.frame(bot)
cps2$id <- seq.int(nrow(cps2))
colnames(cps2) <- c("text", "id")
cps2 <- cps2[c("id", "text")]
Corpus2 <- quanteda::corpus(cps2)
A corpus is the best data structure to perform pre-processing and data cleansing. In this case I'm employing the Quanteda text mining package which is known to perform considerably faster on large Corpi, than the more common and better known tm package.
This first step will attempt to remove URLs and numbers.
Corpus1 <- rm_url(Corpus1, replacement = " ", extract=FALSE, trim=FALSE, clean=TRUE)
Corpus1 <- tm::removeNumbers(Corpus1, ucp = TRUE)
Corpus2 <- rm_url(Corpus2, replacement = " ", extract=FALSE, trim=FALSE, clean=TRUE)
Corpus2 <- tm::removeNumbers(Corpus2, ucp = TRUE)
This next will remove Stop Words and punctuation.
tic("Remove stop words and puctuation")
steem_stops <- c("steem", "steemit", "steemian", "steemians", "resteem", "upvote", "upvotes", "post", "SBD", "jpg", "td", "n", "s", "t", "re", "nbsp", "p", "li", "br", "strong", "quot", "img", "height", "width", "src", "center", "em", "html", "de", "href", "hr", "blockquote", "h1", "h2", "h3", "960", "720", "div", "en", "que","la", "will", "y", "el", "https", "http", "do", "does", "did", "has", "have", "had", "is", "am", "are", "was", "were", "be", "being", "been", "may", "must", "might", "should", "could", "would", "shall", "will", "can", "un", "get", "los", "di", "se", "also", "una", "h", "b", "alt", "_blank", tm::stopwords("en"))
dfm1 <- dfm(Corpus1, tolower=TRUE, stem=FALSE, remove=steem_stops, remove_punct=TRUE)
dfm2 <- dfm(Corpus2, tolower=TRUE, stem=FALSE, remove=steem_stops, remove_punct=TRUE)
topfeatures(dfm1)
topfeatures(dfm2)
tic()
With a corpus free of extraneous words and characters we can now attmpt a cluster analysis using the topicmodel package.
tic("Create LDA Topic Models")
library(topicmodels)
dfm1LDAFit<- LDA(convert(dfm1, to = "topicmodels"), k = 5)
get_terms(dfm1LDAFit, 10)
dfm2LDAFit <- LDA(convert(dfm2, to = "topicmodels"), k = 5)
get_terms(dfm2LDAFit, 10)
toc()
Word Clusters in Top Up Voted Posts
We will employ the Latent Dirichlet Allocation Model (LDA) to perform our cluster analysis.
Interestingly, the algorithm seems to be grouping words by language set. Topics 2 and 4 appear to be a mix of French and Spanish. Topic 3 contains oriental characters. I think they're Chinese and Korean. I'd suggest Top 5 is Indonesian.
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| "one" | "para" | "的" | "e" | "yang" |
| "like" | "por" | "tr" | "che" | "dan" |
| "time" | "con" | "target" | "il" | "ini" |
| "just" | "es" | "content" | "per" | "saya" |
| "people" | "las" | "und" | "le" | "untuk" |
| "now" | "lo" | "die" | "non" | "dengan" |
| "new" | "del" | "我" | "è" | "dari" |
| "see" | "mi" | "の" | "si" | "kita" |
| "make" | "como" | "day" | "con" | "tidak" |
| "day" | "su" | "sub" | "da" | "и" |
Word Clusters in Bottom Down Voted Posts
These appear to be from news press releases that are often time sensitive (short shelf life). Topic 1 appears to be alt-coin and crypto centric. There may be some NSFW content in Topic 3.
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| "source" | "service" | "market" | "payout" | "class" |
| "target" | "source" | "twerk" | "value" | "news" |
| "full" | "twitter" | "hot" | "ago" | "alert" |
| "story" | "@mack-bot" | "girl" | "total" | "target" |
| "read" | "read" | "meme" | "created" | "source" |
| "twitter" | "full" | "report" | "current" | "read" |
| "bitcoin" | "story" | "sexy" | "posted" | "pull-right" |
| "news" | "target" | "research" | "hours" | "full" |
| "ripple" | "news" | "time" | "time" | "story" |
| "ethereum" | "never" | "funny" | "days" | "pull-left" |
Create Document Frequency Matrix
Finally, we can create a document frequency matrix and perfom some spimple word counting. The results are illustrated in the Conclusions section below.
tic("Create DFM & Word Freq")
## Doc Freq Matrix
dfm1.1 <- sort(colSums(dfm1), decreasing=TRUE)
dfm2.1 <- sort(colSums(dfm2), decreasing=TRUE)
dfm1.1.wf <- data.frame(word=names(dfm1.1), freq=dfm1.1)
dfm2.1.wf <- data.frame(word=names(dfm2.1), freq=dfm2.1)
head(dfm1.1.wf, 10)
head(dfm2.1.wf, 10)
toc()
Conclusions
Highest Up Voted Posts
These words appear to be naturally spoken, casual words (as opposed to busines or techical words). They include generally positive and collective verbs. There is a marked lack of text markup characters compared to the Down Voted Posts below.
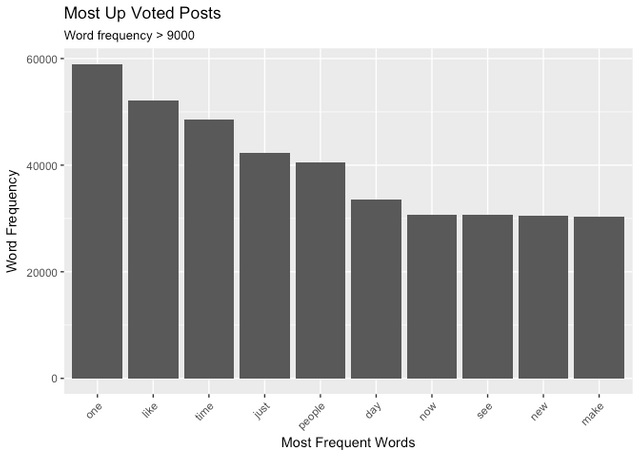
Word Cloud Minimum Word Frequency : 5000
Lexical Dispersion Plot
A lexical dispersion plot allows us to visualize the occurrences of particular terms throughout a Post. These are sometimes referred to as “x-ray” plots. In this example we are looking at posts with more than 1,000 votes and their use of the top 3 most frequent words.
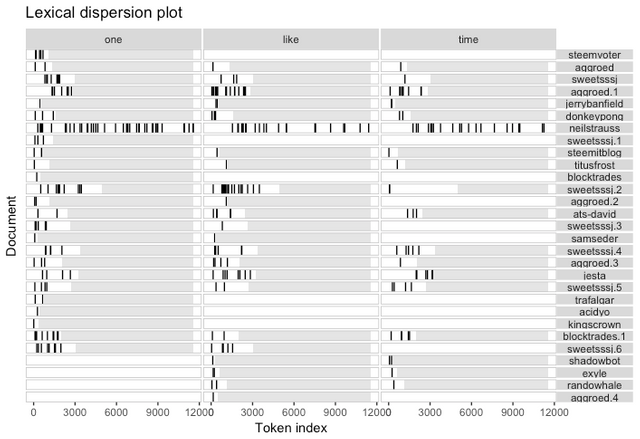
Frequent use of these top occurring words throughout a post are strong markers of a high performing (lots of up votes) post.
There appears to be an obvious distinction between two classes of top performing user.
- High frequency posters publishing short form, short shelf life content. These are the volume players.
- Low frequency posters publishing longer form content with longer shelf life. These are the value players
Lowest Down Voted Posts
This class of post seems to have a heavy emphasis on crypto and alt-coins. This is known to be one of the earliest steemit communities, comprised of day traders and market makers. They are a vocal and opinionated group.
Unsurprisingly, user @mack-bott appears among the most frequent terms. This user is a bot for flagging spam accounts.
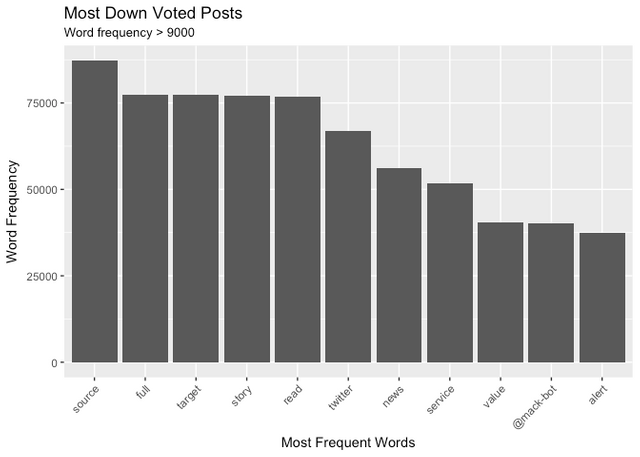
The word cloud identifies several crypto-coin news services. These appear to be automated news submission engines (bots). It's these that are being targeted for down voting by @mack-bot and @patrice. In the early days these may have been useful to the crypt-community mentioned above. Today, the platform seems to have outgrown the need for these news (spam) bots and they've become widely disliked.
For example @bitcoinhub was scraping the internet for news and posting every 10 mins. Their last post was December 12th. Presumably the owner of this bot gave up the battle and conceded defeat to @mack-bot and @Patrice (amongst others)
We owe them a debt of gratitude for keeping this spam out of our feeds.
Word Cloud Minimum Word Frequency : 5000

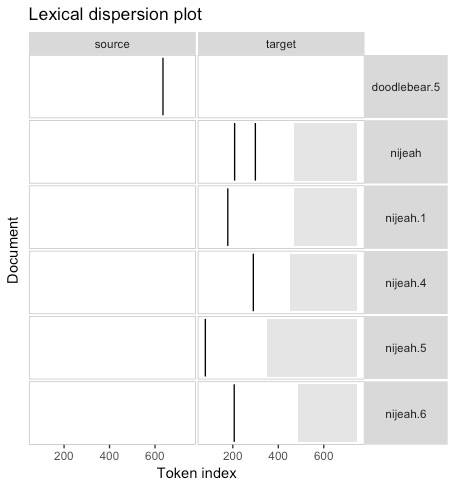
Lexical Dispersion Plot
A lexical dispersion plot of the bottom performing posts (more than -15 down votes) shows curious results. Of the most frequent words ("source", "full", "target") only two appear in texts of the most down voted posts.
The user @nijeah appears to be a crypto trader posting market commentry and involved in a flame war with other users. Aggressive doxing and down voting seems to be at play here.
Posted on Utopian.io - Rewarding Open Source Contributors
Thank you for the contribution. It has been approved.
You can contact us on Discord.
[utopian-moderator]
Hey @crokkon, I just gave you a tip for your hard work on moderation. Upvote this comment to support the utopian moderators and increase your future rewards!
guys check me out! https://steemit.com/btc/@crypto-outlet/crypto-outlet-btc-update-alert-we-broke-7k-support-whats-next
we will be working on a company soon with our own ICO, in the meantime we post about crypto news and analysis!
Please check us out, follow and upvote!
Hey @morningtundra I am @utopian-io. I have just upvoted you!
Achievements
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x
Very interesting and useful information! Thank you for the awesome post. I will try to implement some of the info you provided in my future posts.
I like the writing of your article is very interesting people to comment on your article ,,,
I want tips and tricks from you ,, please help
I like your words that are highly motivated ,, I want to ask for tips and tricks
from you how to write interesting ,, please help.
https://steemit.com/photography/@boyhaqi97/kontes-foto-terbaru-photo-competition-ichitan-2018-provoke
@originalworks
Follow @Sportsatsteem Sports News Live Score Update 24/7 on Steem
Di upvote lah punya kita
Good analysis ...
hopefully you can give me advice
Greeting from me ..
Sure thing. What sort of advice are you seeking?
Nice :). I would be really, really happy, if you guys could look up my paperpiano and tell me, what you think of this :D.
Thank you
Piano Master