🐍📓 Mi agenda Python: #4 Pickle

🐍📓 Mi agenda Python: #4 Pickle
Por Enio...
Nos vemos de nuevo, apreciados lectores y steemianos de #STEM-Espanol, #SteemSTEM, #Curie, #Utopian-io y otras comunidades de Steemit.
Continuamos con nuestra serie Mi agenda Python, enfocada en abordar distintas herramientas de programación relacionadas con el lenguaje de programación Python y que puede abarcar herramientas tales como snippets, scripts, bibliotecas (‘librerías’), frameworks, programas de aplicación, entre otros, siendo una serie que ya hemos presentado anteriormente y en la que abordamos contenidos de manera accesible tanto para el público especialista como el no-especialista. Sin más preámbulos, revisemos la herramienta de esta edición.
Nombre del Recurso
Pickle
Aclarando conceptos...
La mayoría de los programas de aplicación de nuestro escritorio, móvil y casi todo aquel que sea usado a través de la Internet por lo general requiere un frecuente intercambio de información, bien sea enviando y recibiendo dicha información con relación a una fuente ajena (a través de una red) o con relación a una fuente propia que sea parte del sistema en el que se ejecuta el software.
En ambos casos, el intercambio de información muy probablemente implique un proceso de almacenamiento, es decir, que la información sea grabada en algún medio medio de almacenamiento secundario. Es a lo que comúnmente se refieren los usuarios finales cuando hablan de 'guardar y abrir archivos', pero que, no obstante, en ciencias y tecnologías de la computación resulta ser una operación conocida técnicamente como persistencia. Se dice que es persistencia en el sentido de que la información 'persiste' por tiempo prolongado y puede ser 'recuperada' para poder ser utilizada nuevamente.
El origen de la persistencia le sucedió a la memoria RAM, que es la memoria principal del computador desde la época de John von Neumann y su aún-vigente arquitectura. Si bien la memoria RAM es la que carga los datos y programas, lo hace de manera temporal o mientras haya suministro eléctrico (la base de esta tecnología electrónica), de allí que sea altamente rápida, pero volátil. Para poder almacenar los datos independientemente de ello y con más duración se emplean memorias 'secundarias', las cuales hacen un buen trabajo para dar persistencia a la información.
No obstante, la memoria secundaria es demasiado lenta para la ejecución directa de programas. Por ejemplo, si usted lanza muchas aplicaciones en un hardware promedio, notará que mientas algunas se ejecutan bien, otras lo harán muy lentamente. Eso se explica no solamente por el hecho de que la memoria principal esté llena y ocupada con los otros varios programas, sino porque, para poder mantener todas las aplicaciones cargadas y en funcionamiento –como usted espera–, el sistema operativo está temporalmente almacenando la actividad de algunas de esas aplicaciones en el disco duro, el cual es un medio de almacenamiento secundario. Puesto que intercambiar la información temporal desde el disco duro es algo muy lento en comparación con el intercambio desde la memoria RAM, el desempeño será menos óptimo y provocará ese efecto de lentitud con algunos procesos.
Esta prestación que ofrecen los modernos sistemas operativos de apoyarse en la memoria secundaria para auxiliar a la memoria principal cuando esta se encuentra copada, y poder así mantener a flote las aplicaciones abiertas, se llama memoria virtual en el sistema Windows, y swapping en sistemas UNIX-like (tipo UNIX) como GNU/Linux. En la imagen siguiente vemos cómo el monitor de sistema de una de mis computadoras, en un momento determinado, muestra el uso del área de intercambio (swapping).
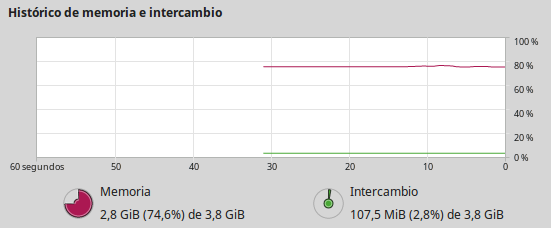
⬆️ Imagen 1: Rendimiento de mi sistema operativo usando el área de intercambio Autor: @Eniolw Licencia: CC BY 2.0
Por supuesto, ello es un ejemplo del papel extendido de la memoria secundaria, que sin embargo, sigue teniendo como norte principal el almacenamiento persistente de la información.
Por lo general, los programas almacenan con persistencia todo aquello que constituya su base de datos o las bases de datos con las que tenga alguna relación, y tales datos dependerán en gran medida de lo que trate la aplicación, que puede ser muchas cosas, desde el simple estado de un videojuego, pasando por transacciones de negocios, hasta un post de Steemit, por ejemplo. Otro método para crear registros persistentes son los ficheros, los cuales forman parte del sistema de archivo del dispositivo de memoria secundaria.
No obstante, en ocasiones, algunos programas necesitarán almacenar en la memoria secundaria información más elaborada, como la de sus propios estados internos. Para un programador, esto se refiere a todos los valores e instancias de objetos que crea y conforma un programa en ejecución. Este tipo de información no es atómica o primitiva, es decir, no está descompuesta en partes indivisibles como pasa con los datos de la mayoría de las bases de datos, sino que es compuesta de varias partes que solo tienen sentido y operatividad en conjunto, por lo que a veces es mejor almacenarla permanentemente tal como está.
Por ejemplo, en una aplicación cliente de la blockchain podría existir un objeto llamado post, el cual posee atributos como título, cuerpo, etiquetas, autor, url, comentarios, recompensas, etc., los cuales, a su vez, pueden ser otros objetos. Los valores exactos que posee el objeto en cada uno de sus atributos en un entorno de ejecución y tiempo determinados le confiere identidad al objeto y constituye un estado concreto. Si uno de los valores es alterado, se dice que el estado no ha persistido, pues ha cambiado.
Dicho objeto puede almacenarse en una memoria secundaria, quizá a través de la descomposición y extracción de sus atributos para almacenarlos individualmente, lo que implica que deben unirse todas las piezas nuevamente a la hora de recuperar el estado, instanciando cada sub-objeto implicado. Esto puede ser conveniente en algunos casos, pero inconveniente en otros, sobre todo cuando se trata de transportar el objeto o si su recuperación implica invertir recursos de procesamiento.
Alternativamente está la serialización. Es una técnica mediante la cual los objetos se codifican a una secuencia de bytes tal como si fuesen una cadena de caracteres, de tal manera que pueden ser representados en una secuencia de datos que puede ser fácilmente escrita en un medio de memoria secundaria. De esta forma, los objetos y su estados pueden ser reconstruidos simplemente recuperando y decodificando la secuencia que los representa. Con esto tiene relación la operación de swapping mencionada anteriormente.
Además, la serialización aporta ventajas adicionales más que solamente almacenamiento, pues permite la transferencia íntegra del objeto a través de una red, quizá para enviarlo a un dispositivo remoto que ejecute una aplicación que lo necesite. En el ejemplo anterior sobre el objeto post, esto cobra sentido por cuanto muchas aplicaciones clientes de la blockchain del Steem pueden descargar la totalidad de la data que constituye a un post codificada en formato JSON y fácilmente reconstruirlo.
Ahora bien, ¿cómo se implementa la serialización? Ello dependerá del lenguaje de programación empleado y nos servirá para presentar la herramienta de esta entrega.
Descripción
Pickle es un módulo de Python que viene incluido en su biblioteca estándar durante su instalación. Se dice que es un 'módulo' puesto que es el término estandarizado dentro del mundo Python y es equivalente al concepto de 'biblioteca' examinado en anteriores entregas; una colección de código con funciones prescritas que simplemente incluimos en nuestros proyectos para facilitar el desarrollo o aprovechar sus prestaciones.
El papel de Pickle es proveer un método simple pero efectivo para llevar a cabo la serialización de objetos dentro de Python. Para ello, Pickle hace la serialización a secuencias de bytes, escribiendolas y leyéndolas desde ficheros para su persistencia. El resultado de la operación, por tanto, será una cadena que generalmente se guarda a un archivo y al que podemos referirnos como 'archivo pickle'.
La serialización puede realizarse como representación de ASCII imprimible, lo que permite que la codificación sea parcialmente legible para los seres humanos (útil en casos de depuración), o como formato binario, lo que sería ilegible para nosotros, pero implicaría eficiencia en el procesamiento.
Como hemos visto, los posibles usos de estos pickes de Python pueden abarcar desde el almacenamiento en ficheros y bases de datos de los datos-objetos producidos por la ejecución de un programa, la realización de copias de seguridad o la transferencia del objeto a través de Internet, etc.
Personalmente he encontrado a Pickle realmente práctico en algunos proyectos en los que puedo prescindir de una base de datos en beneficio de utilizar un archivo de texto plano, en el cual se almacena el estado del objeto sin necesidad de descomponerlo y de almacenar sus partes por separado para luego tener que cargarlas cada una y rearmar al objeto; hacer pickles realmente puede ser cómodo en muchos casos.
Algunas características
- Al ser estándar no hace falta su instalación como módulo externo y viene incluido en todas las versiones de Python.
- Su cometido es la serialización, pero no en todo el entendimiento de la persistencia como proceso, puesto que realmente no se ocupa de interactuar con el sistema de archivos de otra manera que no sea escribir y leer los datos a serializar.
- Se apoya en un módulo interno llamado marshal, el cual realiza una tarea similar a Pickle y su nombre viene de marshalling que significa 'serialización' en inglés.
- Posee una mucho más óptima implementación en lenguaje C conocida internamente como cPickle, puesto que el módulo original de Python es más lento.
- El formato que genera es específico para Python, por lo cual puede ser utilizado exclusivamente dentro de este lenguaje. Ello tiene la ventaja de que permite la serialización de objetos complejos y la desventaja de que las aplicaciones escritas con otros lenguajes no podrán entender ese formato.
Sitio web o repositorio
Ejemplo de uso
Veremos ahora una demostración de uso del módulo a modo de tutorial y ejemplo. Hemos dicho que Pickle viene incluido por defecto, por lo cual no hay que hacer pasos extra de instalación. Para usarlo simplemente importamos el módulo así:
import pickleAhora examinaremos cómo utilizar este módulo para hacer operaciones de serialización (pickling) y de deserialización (unpickling). En primer lugar consideremos la siguiente clase Post y su objeto instancia:
class Post:
def __init__(self, _autor, _titulo, _contenido, _etiquetas, _permlink, _metadata):
self.autor = _autor
self.titulo = _titulo
self.contenido = _contenido
self.etiquetas = _etiquetas
self.permlink = _permlink
self.metadata = _metadata
post = Post(
"eniolw",
"Agenda Python: Pickle",
"...Contenido del post...",
["steemstem", "stem-espanol"],
"asdawewdwefwegefe2343",
{"app": "steemstem"}
)A fin de generar el fichero pickle, crearemos primero un archivo y lo abriremos en modo de escritura en binario. Lo correcto es hacerlo mediante la cláusula with. Luego, usamos la función dump (volcar) del módulo Pickle para poder hacer la serialización. Esta función toma dos argumentos: el objeto a serializar y el destino, que será el archivo creado previamente:
with open("pickle_de_post", "wb") as archivo:
pickle.dump(post, archivo)Si echamos un vistazo al archivo generado puede que, dependiendo del editor y su configuración, se decodifique y visualice con algunas secuencias legibles y otras parcialmente ilegibles o puede que muestre una serie de números hexadecimales.
Ahora bien, es útil saber que se pueden serializar distintos objetos en el mismo fichero, de modo que bajo la anterior cláusula with, podríamos volcar nuevos objetos. Por ejemplo:
pickle.dump({"nombre": "eniolw"}, archivo)
pickle.dump({"pais": "Venezuela"}, archivo)
pickle.dump({"blog": "https://steemit.com/@eniolw"}, archivo)También, es interesante señalar que la serialización no necesariamente tiene que almacenarse en la memoria secundaria, sino registrarla en una variable string. Para ello se usa la función dumps. Nótese que a diferencia de los ejemplos de arriba, esta función posee una s adicional, que viene de string (cadena de caracteres).
post_s = pickle.dumps(post)Con ello podemos usar la variable post_s de distintas maneras, como enviarla por Internet.
Ahora bien, la operación inversa es la deserialización, llamada aquí 'unpickling'. Se trata de decodificar correctamente todo el fichero para poder rearmar el objeto y cargarlo en la memoria principal. La función del módulo Pickle que sirve para eso es load (cargar) y se usa como sigue:
with open("pickle_de_post", "rb") as archivo:
post = pickle.load(archivo)Aquí, la variable post será el objeto deserializado de tipo Post (el primero incluido en el archivo). Si la clase se tratara de un diccionario de Python, podríamos fácilmente comprobarlo si imprimimos el objeto por la salida estándar. Sin embargo, los demás objetos serializados aún no se han recuperado. Para cargar cada uno habrá que ejecutar tantas veces load como veces se hizo dump:
dict1 = pickle.load(archivo)
dict2 = pickle.load(archivo)
dict3 = pickle.load(archivo)Alternativamente, el módulo Pickle posee las clases Pickler y Unpickler, con las cuales se puede hacer exactamente lo mismo que con las funciones mostradas en los scripts anteriores ya que estas últimas son, en realidad, atajos a las mencionadas clases.
Para cerrar, se inserta a continuación el script unificado con todo los códigos usados.
# Importanto el módulo:
import pickle
# Creando la clase de ejemplo:
class Post:
def __init__(self, _autor, _titulo, _contenido, _etiquetas, _permlink, _metadata):
self.autor = _autor
self.titulo = _titulo
self.contenido = _contenido
self.etiquetas = _etiquetas
self.permlink = _permlink
self.metadata = _metadata
def main():
# Instanciando el objeto de ejemplo:
post = Post(
"eniolw",
"Agenda Python: Pickle",
"...Contenido del post...",
["steemstem", "stem-espanol"],
"asdawewdwefwegefe2343",
{"app": "steemstem"}
)
# Serializando el objeto post y otros en ficheros:
with open("pickle_de_post", "wb") as archivo:
pickle.dump(post, archivo)
pickle.dump({"nombre": "eniolw"}, archivo)
pickle.dump({"pais": "Venezuela"}, archivo)
pickle.dump({"blog": "https://steemit.com/@eniolw"}, archivo)
# Deserializando desde ficheros:
with open("pickle_de_post", "rb") as archivo:
post = pickle.load(archivo)
dict1 = pickle.load(archivo)
dict2 = pickle.load(archivo)
dict3 = pickle.load(archivo)
# Serializando sobre un string (dumps):
post_s = pickle.dumps(post)
print (post_s)
if __name__ == '__main__':
main()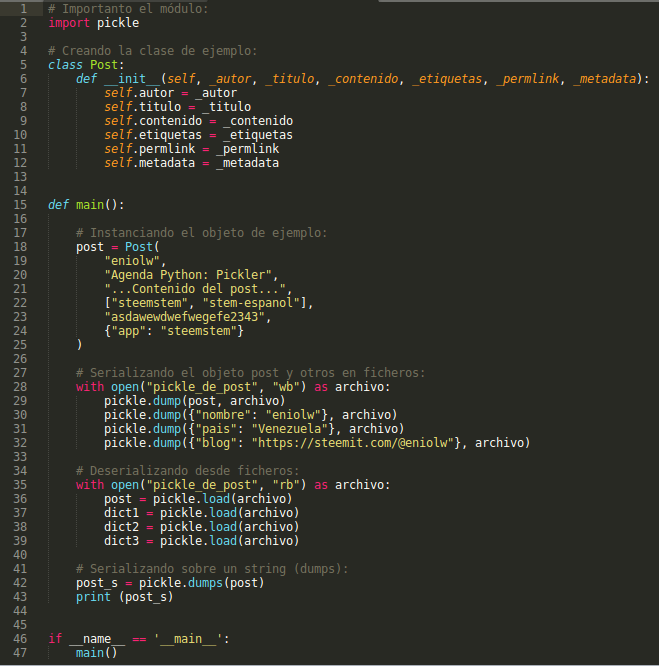
En resumen
Hemos visto que la serialización es una técnica de programación bastante práctica para codificar completos objetos y poder representarlos en su totalidad mediante una secuencia única de bytes, sin tener que descomponer y codificar por separado sus partes. El destino del serializado será, la mayoría de las veces, la persistencia, es decir, el almacenamiento prolongado del objeto, lo cual puede hacerse en una base de datos o en un archivo.
Esto es especialmente útil cuando conviene preservar el estado exacto de un objeto para que pueda ser reutilizado posteriormente o incluso transmitido remotamente. Un ámbito en el cual se aplica la serialización son las operaciones de swapping que realiza el sistema operativo cuando respalda en la memoria secundaria el estado de muchas aplicaciones que no puede mantener por completo en la memoria física principal.
La herramienta de fábrica que posee Python para la serialización es Pickle, un módulo con el cual se generan secuencias en un formato propio que puede representar muchos objetos complejos. Adicionalmente, Pickle aplica el volcado sobre archivos para su persistencia, como también puede mantener la secuencia como string; como prefiera y necesite el programador. Pickle proporciona soluciones prácticas, y cuenta con una implementación en lenguaje C que, de acuerdo a su documentación, es "hasta 1000 veces más eficiente" que la implementación original de Python, pero que naturalmente puede ser invocada y utilizada desde este.
En el futuro continuaremos abordando más herramientas de Python. De momento, si tienes alguna duda o aporte, no dudes en hacerlo saber. Nos vemos.
ALGUNAS FUENTES DE CONSULTA
Si estás interesado en más temas sobre Ciencia, Tecnología, Ingeniería y Matemáticas (STEM, siglas en inglés), consulta las etiquetas #STEM-Espanol y #SteemSTEM, donde puedes encontrar más contenido de calidad y también hacer tus aportes. Puedes unirte al servidor de Discord de STEM-Espanol para participar aún más en nuestra comunidad y consultar los reportes semanales publicados por @STEM-Espanol.

NOTAS ACLARATORIAS
- La imagen de pie es de @CarlosERP-2000 y @IAmPhysical y es de dominio público.
- A menos que haya sido indicado lo contrario, las imágenes de esta publicación han sido elaboradas por el autor, lo que incluye la imagen de banner, creada con base en imágenes de dominio público y en un logo de Python adaptado por Rocket000 y otros (fuente).

This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @utopian-io and @curie.
If you appreciate the work we are doing then consider voting all three projects for witness by selecting stem.witness, utopian-io and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Thank you very much!
In as much as i cant read most of your blog, you pictures seems to talk about technology. And i can sense you really did great. Keep it up
Oh, thank you @ferrate!
You are humbly welcome
Posted using Partiko Android
Saludos @eniolw. Como siempre muy ilustrativo tu post, aunque veo que es una herramienta bastante útil para los programadores el post nos deja claro a los que no estamos tan familiarizados con esta área como es el proceso de almacenamiento e intercambio de información de los software que utilizamos con frecuencia.
Gracias Emilio... De eso se trata, de publicar posts especializados y también posts donde nuestros conocimientos sean también accesibles para muchos. Saludos y gracias por la visita!
Saludos @eniolw, seguimos aprendiendo contigo, gracias por compartir y en espera del conversatorio para ampliar conocimientos!
Gracias por el seguimiento, estimada Doctora @Elvigia. Pronto estaremos con eso. Ya se está "normalizando" el servicio de Internet en varias partes del país. Saludos!
Congratulations @eniolw! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Good news! Thanks
¡LOL! Yo pensaba que Utopian tenía prohibido votar este tipo de publicaciones.. Lo digo sin acritud, pero es que me hace gracia.
Hace tiempo hice una serie de post, y siempre me pusieron complicaciones, por el simple hecho de que no seguia sus estrictas pautas; cuando luego veias trescientos mil publicaciones votadas por ellos; que no seguian ninguna de sus pautas.. De por entonces, te hablo..
Vamos, que basicamente, votan a quién le da la gana. Uno de los más chistosos es uno de los que llevaba los apartados de "blog" que hacía plagios de "tutoriales" de software de hace trescientos años, de una forma explicativa y se lo aceptaban.. & en fin.
A ti al parecer te han aceptado las publicaciones en español, y a mi era una de las grandes pegas que me ponían..
Supongo, que es lo que tiene dedicar tiempo a estar entre ciertas personas y dejarse ver, que te ganen confianza.. xD
A mi jamás me la dieron tampoco la he buscado, la verdad.
Es una pena, pero bueno, ellos sabrán yo no puedo dedicarme a hacerles la pelota; como aquel tal Didac.. 😹
PD: Haber si me pongo en contacto contigo, para organizar mejor mis pautas en futuras publicaciones y que sean tenidas en cuenta.. 😹😹😹🖖
En verdad, haber si puedo reinsertarme un poco por Steemit, supongo que seguis en el grupo de Discord? O donde es que os encontráis más activos?
Hola, @rosepac.
Como se lee en los comentarios, Utopian me votó en cooperación con SteemSTEM, comunidad que cura contenidos sobre Ciencia, Tecnología, Ingeniería y Matemáticas.
Utopian ya se fue de Steem.